任务要求 实现 SQL 的查询处理 。
针对 DML 语句,进行词法、语法、语义分析 ,输出语法分析树; 制定逻辑查询计划 :把语法树转换成一个关系代数表达式,输出分析树对应的逻辑计划和优化后的逻辑计划;制定物理查询计划 :把优化后的逻辑计划转换成物理查询计划,要求指定操作执行的顺序,每一步使用的算法,操作之间的传递方式等。实现架构 完整的查询处理流程:
flowchart TD
A["SQL 字符串(输入)"]
B["1.词法分析:使用 <code>Lexer<code/>"]
C["Token 序列"]
D["2.语法分析:解析 Token 生成 AST"]
E["AST (抽象语法树)"]
F["3.逻辑规划:使用 <code>Planner<code/>"]
G["LogicalPlan (优化前)"]
H["4.查询优化:使用 <code>Optimizer<code/><br/>优化类型: 谓词下推<br/>"]
I["LogicalPlan (优化后)"]
J["5.物理规划:使用 <code>PhysicalPlanner<code/>"]
K["Executor 树(物理执行计划)"]
L["执行结果(Output)<br/><code>ExecutorRecord Stream<code/>"]
A --> B --> C --> D --> E --> F --> G --> H --> I --> J --> K --> L
模块之间的依赖关系为:
flowchart LR
A["词法层<br/><code>sql::lexer</code>"]
B["语法层<br/><code>sql::parser</code><br/><code>sql::ast</code>"]
C["规划层<br/><code>plan::planner</code><br/><code>plan::logical</code>"]
D["优化层<br/><code>plan::optimizer</code>"]
E["物理层<br/><code>plan::physical</code>"]
F["执行层<br/><code>exec::*</code>"]
A --> B --> C --> D --> E --> F
style A fill:#bbdefb
style B fill:#c5cae9
style C fill:#d1c4e9
style D fill:#f8bbd0
style E fill:#ffccbc
style F fill:#c8e6c9
设计思路 词法分析 词法分析的目的是将 SQL 字符串转换为 Token 序列 。
核心实现 :
类: Lexer (位置: src/sql/lexer.rs) 方法: tokenize() - 返回 Vec<Token> 支持的 Token 类型主要有 :
关键字: SELECT, FROM, WHERE, JOIN, INSERT, DELETE, UPDATE, etc. 标识符: 表名、列名等 字面量: 整数、浮点数、字符串 操作符: =, !=, <, >, <=, >=, AND, OR 分隔符: (, ), ,, ; 示例输出 :
1 2 3 4 SQL: "SELECT id, name FROM users WHERE age > 18"
语法分析 语法分析的目的是将 Token 序列转换为抽象语法树 (AST) 。在 src/sql/ast.rs 中实现。
核心实现 :
SelectStmt, InsertStmt, UpdateStmt, DeleteStmt, CreateTableStmt, DropTableStmtSelectStmt 的结构
1 2 3 4 5 6 7 8 9 pub struct SelectStmt {pub distinct: bool ,pub fields: Vec <SelectField>, pub from_table: Option <String >, pub where_clause: Option <WhereClause>, pub group_by: Option <Vec <String >>, pub order_by: Option <Vec <OrderBy>>, pub limit: Option <u32 >,
AST 示例 :
1 2 3 4 5 6 7 8 9 10 11 12 SelectStmt {false ,Column ("id" ), Column ("name" )],Some ("users" ),Some (WhereClause {Column ("age" ),Literal (Integer (18 ))
另外,本项目也实现了一个完整的递归下降解析器 (parser.rs),能使用运算符优先级爬升算法 ,正确处理表达式优先级。例如:
1 2 3 4 5 6 7 8 // 优先级层次(从低到高)
逻辑规划 逻辑规划的目的是将 AST 转换为关系代数表达式(逻辑计划树) 。在 src/plan/planner.rs 中实现。
核心实现 :
类: Planner 方法: plan() → LogicalPlan LogicalPlan 枚举 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 pub enum LogicalPlan {String ,Box <LogicalPlan>,Box <LogicalPlan>,Vec <String >,Box <LogicalPlan>,Box <LogicalPlan>,Option <Expression>,
转换规则 :
SQL 子句 关系代数算子 说明 FROM tableScan(table)表扫描 WHERE conditionFilter(condition, child)选择 (σ \sigma σ SELECT columnsProject(columns, child)投影 (Π \Pi Π JOINJoin(left, right, condition)连接 (⋈ \Join ⋈
示例 :
1 2 3 4 5 SELECT users.name, orders.amountFROM usersJOIN orders ON users.id = orders.user_idWHERE users.age > 18 AND orders.status = 'paid' ;
生成的逻辑计划树:
1 2 3 4 5 6 Project([users.name, orders.amount]) // 查询
查询优化 查询优化的目的是优化逻辑查询计划以提高执行效率 。在 src/plan/optimizer.rs 中实现。
核心实现 :
类: Optimizer 方法: optimize() → LogicalPlan 优化技术 主要有:
谓词下推 外连接处理 谓词下推 谓词下推就是将 WHERE 条件尽可能下推到 Scan 算子 ,将过滤条件尽可能下推到数据源附近 ,减少中间结果集的大小。
σ condition ( R ⋈ S ) = σ condition R ( R ) ⋈ σ condition S ( S ) \sigma_\text{condition}(R \Join S) = \sigma_{\text{condition}_R}(R) \Join \sigma_{\text{condition}_S}(S) σ condition ( R ⋈ S ) = σ condition R ( R ) ⋈ σ condition S ( S )
其中:
σ \sigma σ 选择 操作(WHERE)⋈ \Join ⋈ 连接 操作(JOIN)condition R \text{condition}_R condition R 只涉及 R R R condition S \text{condition}_S condition S 只涉及 S S S 实现算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 impl Optimizer {pub fn optimize (&self , plan: LogicalPlan) -> Result <LogicalPlan, String > {match plan {let optimized_child = self .optimize (*child)?;self .push_down_predicate (predicate, optimized_child)fn push_down_predicate (self ,-> Result <LogicalPlan, String > {match child {Ok (LogicalPlan::Scan {let (left_preds, right_preds, join_preds) = self .split_predicate (&predicate, &left, &right)?;let opt_left = self .push_predicates_to_child (left_preds, *left)?;let opt_right = self .push_predicates_to_child (right_preds, *right)?;Ok (LogicalPlan::Join {Box ::new (opt_left),Box ::new (opt_right),Ok (child),
示例 :
优化前 :
1 2 Filter(age > 18)
优化后 :
1 Scan (users, predicate=age > 18 )
外连接处理 外连接的查询优化比较复杂,因为外连接需要保留某一侧的所有行 ,所以:
本项目进行外连接处理的规则是外连接上的 Filter 不下推到两个表 ,只推到相关表 。
JOIN 类型左表条件 右表条件 INNER JOIN可下推 可下推 LEFT JOIN可下推 不可下推 RIGHT JOIN不可下推 可下推 FULL OUTER JOIN不可下推 不可下推
优化前:
1 2 Filter(users.status = 1)
优化后:
1 2 Filter(users.status = 1)
优化示例 :
1 2 3 4 5 6 7 8 SQL: "SELECT * FROM users WHERE age > 18"
物理规划 物理规划就是将逻辑计划转换为具体的执行计划(Executor 树) 。在 src/plan/physical.rs 实现。
本项目采用的是经典的 Volcano 迭代模型 (也称为 Pipeline 模型)。核心思想是每个算子(operator)都实现一个统一的函数接口:next()。
模型特点 :
拉取式 :父算子从子算子拉取数据,调取它的 next()流式处理 :一次处理一条记录,这样内存占用小流水线 :多个算子可以并行工作核心实现 :
类: PhysicalPlanner 方法: plan() → Box<dyn Executor> 逻辑算子到物理算子的映射 :
逻辑算子 物理算子 位置 ScanSeqScanExecutorsrc/exec/scan.rsFilterFilterExecutorsrc/exec/filter.rsJoinNestedLoopJoinExecutorsrc/exec/join.rs
Executor 基类 (Volcano 模型):
1 2 3 4 5 6 7 8 9 10 pub trait Executor {fn init (&mut self ) -> Result <(), String >; fn next (&mut self ) -> Result <Option <ExecutorRecord>, String >; fn close (&mut self ) -> Result <(), String >; pub struct ExecutorRecord {pub rid: RID, pub data: Vec <u8 >,
主要实现有:
SeqScanExecutor(顺序扫描)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 pub struct SeqScanExecutor {impl Executor for SeqScanExecutor {fn next (&mut self ) -> Result <Option <ExecutorRecord>, String > {for page_id in &self .data_pages {let page = self .buffer_manager.fetch_page (*page_id)?;for slot_id in 0 ..slots_per_page {if is_slot_valid (page, slot_id) {return Ok (Some (read_record (page, slot_id)));Ok (None )
FilterExecutor(过滤)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 pub struct FilterExecutor {Box <dyn Executor>,impl Executor for FilterExecutor {fn next (&mut self ) -> Result <Option <ExecutorRecord>, String > {loop {match self .child.next ()? {Some (record) => {if self .evaluate_predicate (&record, &self .predicate)? {return Ok (Some (record)); None => return Ok (None ),
物理计划示例 :
1 SELECT name FROM users WHERE age > 18 ;
执行流程 :
Executor 树 :
1 2 FilterExecutor (age > 18 )SeqScanExecutor (users )
执行流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 1. FilterExecutor.init()
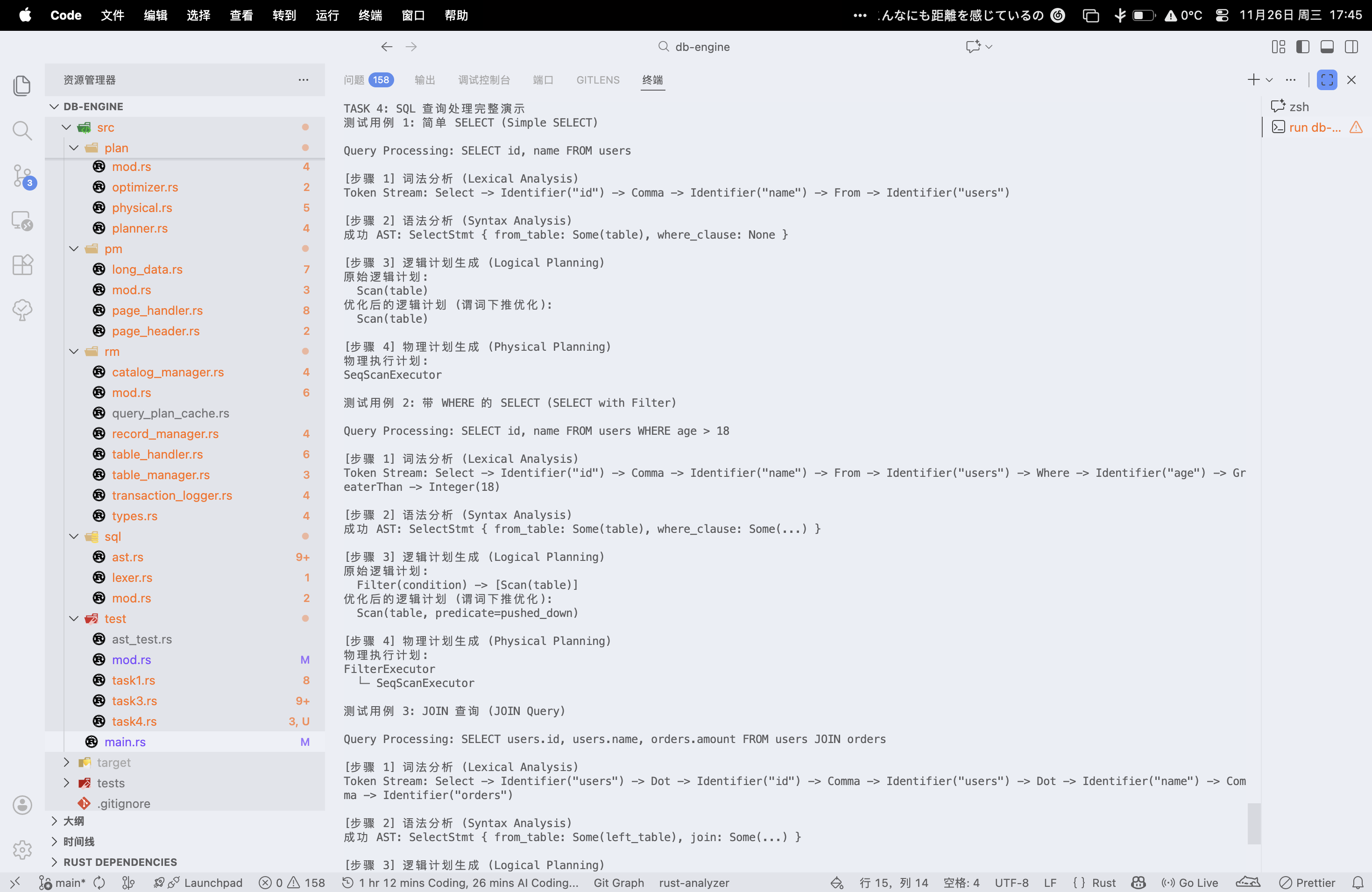
测试与验证 本项目为 task4 设计了一个完整的查询处理演示框架 ,每个测试用例展示从 SQL 到执行结果的全流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #[derive(Debug, Clone, PartialEq)] struct AnalysisResult {String , String , String , String , String , String , fn demonstrate_query_processing (sql: &str ) -> Result <AnalysisResult, String > {println! ("\n[步骤 1] 词法分析" );let tokens = lexical_analysis (sql)?;println! ("\n[步骤 2] 语法分析" );let ast = syntax_analysis (sql)?;println! ("\n[步骤 3] 逻辑计划生成" );let (original, optimized) = logical_plan_generation (sql)?;println! ("\n[步骤 4] 物理计划生成" );let physical = physical_plan_generation (sql)?;Ok (AnalysisResult { sql, tokens, ast, original, optimized, physical })
测试用例设计 完整的测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 fn query (sql: &str ) -> Result <AnalysisResult, String > {println! ("\nQuery Processing: {}" , sql);println! ("\n[步骤 1] 词法分析 (Lexical Analysis)" );let tokens_summary = lexical_analysis (sql)?;println! ("{}" , tokens_summary);println! ("\n[步骤 2] 语法分析 (Syntax Analysis)" );let ast_summary = syntax_analysis (sql)?;println! ("{}" , ast_summary);println! ("\n[步骤 3] 逻辑计划生成 (Logical Planning)" );let (original_plan, optimized_plan) = logical_plan_generation (sql)?;println! ("原始逻辑计划:\n {}" , original_plan);println! ("优化后的逻辑计划 (谓词下推优化):\n {}" , optimized_plan);println! ("\n[步骤 4] 物理计划生成 (Physical Planning)" );let physical_plan = physical_plan_generation (sql)?;println! ("物理执行计划:\n{}" , physical_plan);Ok (AnalysisResult {to_string (),pub fn task4 () -> Result <(), String > {println! ("TASK 4: SQL 查询处理完整演示" );println! ("测试用例 1: 简单 SELECT (Simple SELECT)" );let _result1 = query ("SELECT id, name FROM users" )?;println! ("\n测试用例 2: 带 WHERE 的 SELECT (SELECT with Filter)" );let _result2 = query ("SELECT id, name FROM users WHERE age > 18" )?;println! ("\n测试用例 3: JOIN 查询 (JOIN Query)" );let _result3 = query ("SELECT users.id, users.name, orders.amount FROM users JOIN orders" println! ("\n测试用例 4: 复杂查询 (Complex Query)" );let _result4 = query ("SELECT users.id, users.name FROM users WHERE users.status = 1" println! ("\nTask 4 完成! 所有查询处理流程演示成功\n" );Ok (())
简单的 SELECT 1 SELECT id, name FROM users
处理过程 :
词法分析 : SELECT, id, name, FROM, users语法分析 : SelectStmt { fields: [id, name], from_table: users }逻辑规划 : Scan(users)优化 : 无优化空间物理规划 : SeqScanExecutor(users)预期输出 : 返回 users 表的所有记录
带 WHERE 的 SELECT 1 SELECT id, name FROM users WHERE age > 18
处理过程 :
词法分析 : SELECT, id, name, FROM, users, WHERE, age, >, 18语法分析 : SelectStmt { where_clause: BinaryOp(age > 18) }逻辑规划 : Filter(age > 18) → Scan(users)优化 : 谓词下推 ,Scan(users, age > 18 pushed_down)物理规划 : FilterExecutor → SeqScanExecutor优化效果 : 将 WHERE 条件推入 Scan,减少返回的记录
预期输出 : 返回 age > 18 的用户记录
JOIN 查询1 2 SELECT users.id, users.name, orders.amount FROM users JOIN orders
处理过程 :
词法分析 : 识别 JOIN 关键字语法分析 : SelectStmt { join: Some(...) }逻辑规划 : Join → [Scan(users), Scan(orders)]优化 : 无 WHERE,无优化物理规划 : NestedLoopJoinExecutor → [SeqScanExecutor(users), SeqScanExecutor(orders)]执行方式 : 嵌套循环 JOIN(笛卡尔积)
预期输出 : 返回两表的 JOIN 结果
复杂查询 1 SELECT users.id, users.name FROM users WHERE users.status = 1
处理过程 :
词法分析: SELECT, users.id, users.name, FROM, users, WHERE, users.status, =, 1 语法分析: SelectStmt { where_clause: BinaryOp(status = 1) } 逻辑规划: Filter(status = 1) → Scan(users) 优化: 谓词下推 → Scan(users, status = 1 pushed_down) 物理规划: FilterExecutor → SeqScanExecutor 预期输出 : 返回 status = 1 的用户记录
测试结果 程序输出实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 TASK 4: SQL 查询处理完整演示