软件工程课程部分内容归纳
前面的大部分内容使用 NotebookLM 完成。
各种模型
您要求归纳各种软件过程模型的特点/原理及其适合的场景。根据您提供的资料,以下是几种主要的软件过程模型及其归纳:
| 软件过程模型 | 特点/原理 | 适合的场景 | 关键阶段 |
|---|---|---|---|
| 瀑布模型 | 阶段间具有严格的顺序性与依赖性(前一阶段完成才能开始后一阶段)。推迟实现的观点(清楚区分逻辑设计与物理设计)。是文档驱动的模型,每个阶段结束前需提交合格文档并进行评审。 | 需求必须是完整、准确且稳定不变的项目。适用于需求非常明确、变化性低的中小型项目。 | 线性阶段: 需求分析 → 设计 → 编码/测试 → 综合测试 → 维护 |
| V 模型 | 是瀑布模型的变体和改进。强调测试活动与分析和设计之间的关联(从构造到验证的V形路径)。关注点是软件开发各阶段的活动以及正确性。 | 需要强调软件的验证与确认(Verification & Validation)过程的项目。适用于需求相对稳定不变的项目。 | 构造过程(自顶向下): 需求分析 → 系统设计 → 程序设计 → 编码。验证过程(自底向上): 单元测试/集成测试 → 系统测试 → 验收测试。 |
| 原型模型 (快速原型) | 快速建立一个可运行的模型(功能是最终产品的一个子集)。目的是通过与用户交互来统一客户和开发人员对软件需求的理解,有助于需求的定义和确认。 | 适用于需求模糊、不完整或经常变化的项目,,用于收集客户的真实需求。 | 迭代循环: 快速分析 → 快速构造原型 → 运行原型 → 评价原型(若不满意则快速修改原型,满意则形成最终系统)。 |
| 增量模型 (渐增式开发) | 将软件产品作为一系列增量构件来设计、编码、集成和测试。每个增量都发布一个高质量的可操作版本。能有计划地管理技术风险。 | 人员配备不充裕,或需要在较短时间内向用户交付部分核心功能的项目。要求系统架构具有开放性,以便新增的构件能够无缝集成。 | 阶段性线性开发: 需求分析/验证 → 规格说明/验证 → 概要设计/验证 → (针对每个构件) 详细设计、编码、集成、测试后交付客户。 |
| 螺旋模型 (迭代式开发) | 核心原则是风险分析,相当于在瀑布模型的每个阶段开始前都引入风险分析过程和快速原型。开发过程分成多个迭代,不断改进和完善系统,。 | 大型软件项目的开发。高风险项目,需要持续对风险进行识别和消除。 | 迭代循环的四个任务区域: 1. 制定计划(确定目标、限制) → 2. 风险分析(识别和消除风险) → 3. 实施工程(开发、验证) → 4. 客户评估(评价并计划下一阶段)。 |
| 喷泉模型 | 面向对象范型(面向对象是其特点)。开发活动可以重叠、交叉,体现了面向对象方法学要求开发活动进行迭代或求精的特点。 | 面向对象方法学的开发项目。适用于强调迭代和非线性开发的项目。 | 迭代阶段(可重叠): 需求阶段 → 面向对象分析 → 面向对象设计 → 编码 → 集成和测试 → 运行状态。 |
| 统一过程 (RUP) | 是一个过程框架和详细的规定性过程模型。基于面向对象(OO)和UML。具有二维迭代性(时间轴和内容轴)。核心实践是用例驱动、以架构为中心(基于组件的架构)和迭代式开发,。 | 大型、复杂的、需要明确定义的面向对象结构的项目,。适用于需要降低风险和适应需求变化的项目。 | 四个工作阶段(时间轴): 初始阶段(Inception) → 细化阶段(Elaboration) → 构造阶段(Construction) → 移交阶段(Transition)。九个核心工作流(内容轴): 包括业务建模、需求、分析与设计、实现、测试、部署等。 |
| 敏捷过程 (如 XP、SCRUM) | 价值观是响应变化胜过遵循计划,可工作的软件胜过文档。强调个体和交互,采用短交付周期(如XP的每两周一次迭代),。目标是对变化和不确定性反应更快速、更敏捷。 | 需求模糊且经常改变的场合。需要客户深度参与和快速、持续交付的项目。 | 整体过程: 用户故事/隐喻 → 制订交付计划 → 迭代开发 → 验收测试 → 小交付。迭代周期强调短交付周期(如每两周一次迭代)、结对编程、每日站会等实践。(极限编程) |
英文简称
| 英文简称 | 概念/全称 | 用法/定义 | 出现部分 |
|---|---|---|---|
| COTS | Commercial off-the-shelf (通用商业软件包) | 描述一种引发角色交叉的新情况 (例如,客户、开发者和用户角色可能交叉)。 | 软件工程学概述 (人员角色) |
| CASE | Computer-Aided Software Engineering (计算机辅助软件工程) | 指集成的软件工具,为软件工程方法提供自动或半自动的软件支撑环境。 | 软件工程方法学 |
| RUP | Rational Unified Process (统一理性过程) | 一个过程框架和详细的规定性过程模型,基于面向对象(OO)原则和统一建模语言(UML)。 | 软件过程 |
| UML | Unified Modeling Language (统一建模语言) | RUP基于UML进行设计和文档化;UML是可视化建模基础,包括9种图和4种关系。 | 软件过程/面向对象方法学引论 |
| OO | Object-Oriented (面向对象) | RUP基于OO的原则;面向对象方法学的简称。 | 软件过程 |
| DFD | Data Flow Diagram (数据流图) | 是描绘系统逻辑模型的传统工具,用于表示数据在系统各部件之间的流动情况。 | 可行性研究 (数据流图) |
| PM | Person-Month (人月) | 衡量软件工作量(时间)的单位。 | 成本/效益分析 |
| LOC | Lines of Code (代码行) | 衡量软件规模的单位。用于代码行技术估算软件规模。 | 成本/效益分析/软件项目管理 (成本估算) |
| 4GL | Fourth Generation Language (第四代语言) | 一种独立于具体处理机、面向结果的非过程式语言。 | 需求分析 (获取需求方法) |
| 4GT | Fourth Generation Technology (第四代技术) | 以4GL为核心的软件开发技术。 | 需求分析 (获取需求方法) |
| SRS | Software Requirement Specificatio (软件需求规格说明书) | 用自然语言完整、准确地描述系统的数据要求、功能需求、性能需求等。 | 需求分析 (分析建模与规格说明) |
| ER | Entity-Relationship (实体-联系) | 实体-联系图 (ER图) 是概念性数据模型的一种图形表示,用于描述数据对象、属性和关系。 | 需求分析 (实体-联系图) |
| 1NF/2NF/3NF | First/Second/Third Normal Form (第一/二/三范式) | 定义消除数据冗余的程度。 | 需求分析 (数据规范化) |
| IPO | Input/Processing/Output (输入/处理/输出图) | 描绘输入数据、对数据的处理和输出数据之间关系的图形工具。在总体设计阶段用于简要描述模块算法。 | 需求分析 (其他图形工具)/总体设计 |
| PNG | Petri Net Graph (Petri网) | 用于表达异步系统的控制规则的图形表示法,适用于描述和分析并发执行的处理系统。 | 需求分析 (其他图形工具) |
| PDL | Process Design Language (过程设计语言) | 过程规格说明的语言工具,也被称为伪代码,用正文形式表示数据和处理过程。 | 总体设计/详细设计 |
| SD | Structured Desig (结构化设计方法) | 指基于数据流的设计方法,将信息流映射成软件结构。 | 总体设计 (面向数据流的设计方法) |
| SC | Structure Chart (结构图) | 描绘软件结构(模块和模块间的调用关系)的图形工具。 | 总体设计 (描绘软件结构) |
| SA | Software Architecture (软件体系结构) | 对子系统、软件系统构件以及它们之间相互关系的描述。 | 软件体系结构 |
| C/S | Client/Server (客户/服务器) | 一种体系结构风格,客户请求服务,服务器响应请求,基于资源不对等关系,旨在实现资源共享。 | 软件体系结构 |
| GUI | Graphical User Interface (图形用户界面) | 在三层C/S结构中,指表示层,担负用户与应用间的对话功能。 | 软件体系结构 |
| N-S图 | Nassi-Shneiderman Diagram (盒图) | 一种图形化详细设计工具,可以逐步细化地实现,其功能域明确,容易表现嵌套关系。 | 详细设计 (过程设计技术和工具) |
| PAD图 | Problem Analysis Diagram | 日本日立公司发明的,用二维树形结构图表示程序控制流,支持结构化编程和逐步求精。 | 详细设计 (过程设计技术和工具) |
| V(G) | Cyclomatic Complexity (环形复杂度) | 根据程序控制流的复杂程度定量度量程序复杂程度的方法,计算公式之一为 。 | 程序复杂程度的定量度量 |
| R/A | Reliability/Availability (可靠性/可用性) | 可靠性是程序在给定时间间隔内成功运行的概率;可用性是程序在给定时间点成功运行的概率。 | 软件可靠性 |
| MTTF/MTTR | Mean Time To Failure/Mean Time To Repair (平均无故障时间/平均维修时间) | MTTF是系统成功运行的平均时间;MTTR是修复一个故障平均需要的时间。用于计算稳态可用性。 | 软件可靠性 |
| WBS | Work Breakdown Structure (工作分解结构) | 以可交付成果为导向的项目成分分组,用于组织和定义整个项目范围。 | 软件项目进度计划 |
| FP | Function Point (功能点) | 一种估算软件规模的指标,依赖对软件信息域特性和软件复杂性的评估结果。 | 软件项目管理 (规模估算) |
| UFP/TCF | Unadjusted Function Point/Technical Complexity Factor (未经调整的功能点计数/技术复杂度因子) | 用于功能点(FP)计算的中间变量。FP = UFP × TCF。 | 软件项目管理 (规模估算) |
| EAF | Effort Adjustment Factor (工作量调整因子) | COCOMO模型中的因子,用于调整估算的工作量。 | 软件项目管理 (成本估算) |
| RPD/DD/CUT/IT | Requirement Plan and Product Design/Detailed Design/Coding and Unit Test/Integration Test (需求计划和产品设计/详细设计/编码和单元测试/集成测试) | 高级COCOMO模型中采用的软件生存周期阶段。 | 软件项目管理 (COCOMO模型) |
| SCM | Software Configuration Management (软件配置管理) | 软件系统发展过程中管理和控制变化的规范,目标是标识、控制和报告变更。 | 软件配置管理 |
| SCI | Software Configuration Item (软件配置项) | 为了配置管理而作为单独实体处理的一个工作产品或一段软件,即软件过程输出的全部计算机程序、文档、数据。 | 软件配置管理 |
| CM | Configuration Management (配置管理) | 软件配置管理的简称,如“CM聚集”指SCI的组合。 | 软件配置管理 |
| CRF | Change Request Form (变更请求表) | 用户填写,用于发起典型的变化控制过程。 | 软件配置管理 (变化控制) |
| SQA | Software Quality Assurance (软件质量保证) | 一门学科或一个小组,通过确保软件过程的质量来保证软件产品的质量。 | 软件质量保证 |
| CMM | Capability Maturity Model (能力成熟度模型) | 一个持续的过程改进框架,将过程改进组织为五个成熟度等级。 | 能力成熟度模型 |
公式归纳
软件质量度量
软件质量要素 的度量值由其对 种评价准则的测量值加权求和得出:
其中, 是软件质量要素 对第 种评价准则的测量值, 是相应的加权系数。
环形复杂度计算公式(McCabe 方法)
程序的环形复杂度 可以通过以下三种方法计算,其中 为程序的流图:
根据流图中的区域数计算:
- $ V(G) = \text{区域数} $
根据流图中的边数和结点数计算(欧拉公式):
$ V(G) = E - N + 2 $
是流图中边的条数
是结点数
根据流图中的判断数目计算:
- $ V(G) = P + 1 $
- 是流图中判断(判定节点)的数目
成本估算中的期望值(专家经验法)
在成本估算时,如果使用专家经验法估算出:
- 乐观值
- 悲观值
- 最可能值
- 则计算期望值 的公式为
- 这用于得出估算的工作量
货币的时间价值和现值
在进行成本/效益分析时,涉及货币的时间价值计算:
- 计算 年后的将来值 : 若现在存入的钱数为 ,银行年利率为 ,年数为 ,则 年后可获得的钱数 为: $ F = P(1+i)^n $
- 计算 年后的钱数 的现在价值 : $ P = \frac{F}{(1+i)^n} $ (给出了 的表格列,用于计算将来值或现值)
功能点计算
功能点(FP)是衡量软件规模的指标,计算公式为: $ \text{FP} = \text{UFP} \times \text{TCF} $ 其中:
- 是未经调整的功能点计数(根据信息域参数的计数和复杂度权重求得的加权和)。
- 是技术复杂度因子,其计算公式为: $ \text{TCF} = 0.65 + 0.01 \left( \sum F_i \right) $ 其中, 是所有 14 项技术复杂度因子 的评分总和。
COCOMO 模型
COCOMO (COCOMO 81) 模型用于估算工作量和开发时间,其一般形式如下:
- 工作量 (人月)的估算公式: $ E = a \times (\text{KLOC})^b \times \text{EAF} $ 其中, 是千行代码数, 是工作量调整因子。
- 开发时间 (月/年)的估算公式: $ T = c \times E^d $ 其中, 为工作量(人月), 为取决于项目类型的经验常数。
软件可靠性和平均无故障时间估算
稳态可用性 的计算公式:
- 基于停机时间 和正常运行时间 的计算: $ A = \frac{\sum T_{成功}}{\sum T_{成功} + \sum T_{故障}} $
- 基于平均无故障时间 和平均维修时间 的计算: $ A = \frac{MTTF}{MTTF + MTTR} $
估算平均无故障时间 的经验公式:
其中:
- 是测试前程序中错误总数。
- 是程序长度(机器指令总数)。
- 是在 至 期间改正的错误数。
- 是经验常数(典型值为 200)。
由此公式可推导出估算已改正错误数 的公式:
植入错误法估算原有错误总数 的公式:
假设人为植入的错误数为 ,测试后发现 个植入的错误,以及 个原有的错误,则程序中原有错误的总数 估计为:
分别测试法估算测试前错误总数 的公式:
假设 是测试员甲发现的错误数, 是测试员乙发现的错误数, 是两人发现的相同错误数,则测试前程序中的错误总数 估计为:
计算题和设计题
工程网络图与关键路径
考查形式:
给出一个任务列表(任务名、持续时间、前导任务):
- 画出工程网络图(AOE网)。
- 计算每个事件的最早开始时间(EET)和最晚开始时间(LET)。
- 找出关键路径。
- 计算某项任务的机动时间。
解题步骤:
画图(圆圈+箭头):
- 圆圈:代表“事件”(时刻),如“任务A开始”或“任务A结束”。
- 箭头:代表“活动”(任务),箭头上标注任务名和持续时间(如 A:3)。
- 虚线箭头:表示依赖关系,但不需要时间(持续时间为0)。如果表格里写 B、C完成后才能做D,画图时B和C的箭头汇聚到一个圆圈,然后从这个圆圈引出D。
计算最早时刻 EET (Early Event Time):
- 方向:从左往右(从起点到终点)。
- 规则:
EET(当前节点) = EET(前一节点) + 任务持续时间。 - 重点:如果有多个箭头汇聚到一个节点,取最大值!
计算最晚时刻 LET (Late Event Time):
- 方向:从右往左(从终点倒推回起点)。
- 起点:终点的LET = 终点的EET。
- 规则:
LET(当前节点) = LET(后一节点) - 任务持续时间。 - 重点:如果有多个箭头从一个节点发散出去,倒推时取最小值!
找关键路径:
- 定义:EET = LET 的节点连成的路径。
- 或者:耗时最长的那条路径。
计算机动时间 (Slack Time):
- 公式:
机动时间 = 终点LET - 起点EET - 持续时间。 - 注意:关键路径上的任务,机动时间永远为 0。
- 公式:
真题实例:
如果算出路径 1->2->3->4->6->7->8 的总时间最长,那它就是关键路径。
基本路径测试与环形复杂度
这是白盒测试的经典题型,通常结合流图(Flow Graph)考察。
考查形式:
给一段代码(或流程图),让你:
- 画出控制流图。
- 计算环形复杂度 。
- 写出独立路径。
- 设计测试用例。
解题步骤:
画流图:
- 把流程图里的“方框”(语句)变成圆圈(节点)。
- 把菱形(判断)变成圆圈,引出两条线(True/False)。
- 注意复合条件:如果代码里有
IF A OR B,在流图中要拆成两个判断节点(先判A,再判B)。
计算环形复杂度 (三种算法,结果一样,任选其一验证):
- 公式1(最推荐):。
- 判定节点就是引出两条或多条箭头的节点。
- 公式2:$V(G) = E - N + 2 $。
- :边数(箭头数),:节点数(圆圈数)。
- 公式3:。
- 数一下图里有几个“圈圈区域”,加上外面无边无际的区域。
- 公式1(最推荐):。
写独立路径:
- 数量等于 。
- 必须保证每一条路径至少包含一条之前没走过的边。
- 技巧:先写一条最直的主干路,然后每次改一个分支路口。
设计测试用例:
- 针对每一条路径,反推需要输入的变量值(如
Input A=3, B=0预期输出X=...)。
- 针对每一条路径,反推需要输入的变量值(如
DFD 映射为软件结构图
这是“面向数据流的设计方法”,也就是变换分析。这道题要背步骤。
考查形式:
给一个数据流图(DFD),让你把它转换成软件结构图(SC图,就是那个像组织架构图一样的方块图)。
解题“七步法”(背诵):
- 复查基本系统模型。
- 复查并精化数据流图。
- 确定数据流图具有变换特性还是事务特性(一般考变换型)。
- 确定输入流和输出流的边界,孤立出变换中心。
- 完成“第一级分解”。
- 完成“第二级分解”。
- 使用启发式规则精化。
画图技巧(核心):
- 找边界:在 DFD 图上画两条竖虚线。
- 左边是“物理输入”变成“逻辑输入”的过程(传入分支)。
- 右边是“逻辑输出”变成“物理输出”的过程(传出分支)。
- 中间夹着的就是变换中心(最核心的计算逻辑)。
- 画结构图:
- 顶层写一个主控模块(如“主控XX系统”)。
- 第二层分三叉:左边管输入(Get…),中间管处理(Transform…),右边管输出(Put…)。
- 第三层:把DFD里的圆圈(加工)挂在对应的分支下。
软件可靠性 MTTF 计算
只需要理解三个概念:
MTTF (Mean Time To Failure):
- 意思:平均无故障时间。
- 直白理解:软件“活”多久才会死一次。
- 规律:软件里的错误(Bug)越少,MTTF 就越长(活得越久)。MTTF 与 剩余错误数 成反比。
植入错误法 / 双人测试法(捕获-再捕获模型):
- 这是用来估算总错误数的方法。
- 原理:就好比估算池塘里有多少条鱼。
- 先捞一网鱼(甲发现的错误),做上标记放回去。
- 再捞一网鱼(乙发现的错误),看看里面有多少是有标记的(共同发现的错误)。
- 通过比例,就能算出池塘里总共有多少鱼(总错误数)。
K (常数):
- 这是公式里的一个调节参数,和代码长度、测试质量有关。但在解题时,它其实就是一个“中间商”,算出它就能算出下一步。
必背的两个公式:
- 估算总错误数( 或 )
- :甲发现的错误数。
- :乙发现的错误数。
- :两人都发现的(重合的)错误数。
- :估计的程序总错误数。
- :指令长度。
- MTTF 与 错误数的关系
教科书上的公式很复杂:。
为了考试,我们把它简化成“解题版公式”:
或者展开写成:
- :总错误数(由公式1算出)。
- :已经被你修好的错误数。
- :就是剩余错误数。
题目描述(综合了2011、2014、2017及平时作业题):
在测试一个长度为 48000 条指令()的程序时。
第一阶段:由甲、乙两名测试员独立测试。
- 甲发现并改正了 20 个错误()。
- 此时,MTTF 达到了 8 小时。
- 与此同时,乙发现了 24 个错误(),其中有 6 个是甲也发现的()。
问题:
- 刚开始测试时,程序中总共有多少个潜藏的错误?
- 为使 MTTF 达到 240 小时,必须再改正多少个错误?
解题步骤:
第一步:算出总共有多少个Bug ()
利用“捕获-再捕获”公式(也就是甲乙两个人的数据):
答:刚开始程序中总共有 80 个潜藏错误。
第二步:分析“当前状态”
题目说:“甲发现并改正了 20 个错误,此时 MTTF = 8h”。
- 总错误数 = 80。
- 当前已改正 = 20。
- 当前剩余错误数 = 。
- 当前 MTTF = 8。
根据“反比例关系”(错误越少,时间越长),我们可以算出一个常数关系:
(注:如果你想用老师课件里的 值公式,原理是一样的,只是多除以了一个代码行数 。为了拿满过程分,你可以写:,但在计算最后结果时,这个 会被约掉,所以用我的 算最快且不容易错。)
第三步:计算“目标状态”
题目要求:“使 MTTF 达到 240 小时”。
- 目标 MTTF = 240。
- 目标剩余错误数 = ?
利用刚才算出的常数 :
意思是:只要系统里只剩 2 个 Bug,就能达到 240 小时的无故障时间。
第四步:计算“还需要改正多少”
这是最容易掉进陷阱的一步!
- 现在还剩:60 个错误(80总数 - 20已改)。
- 目标只剩:2 个错误。
- 还需要改: 个。
(注意:一定要看清题目问的是“总共改正多少”还是“再改正多少”。这里问“再”,就是差值。)
答:必须再改正 58 个错误。
避坑指南(考试注意事项)
关于 (代码行数/指令数):
- 题目里给的“48000条指令”、“60000条指令”,在计算 和最终错误数时通常是用不上的(也就是个干扰项,或者仅在写 的定义式时充当分母)。
- 除非:题目强制要求你“求出比例常数 的值”,那你就要用公式 来算一下。一般情况下,直接用上面的“反比例法”算出的结果是完全正确的。
关于“甲改正,乙没改”:
- 题目通常会说“甲发现并改正…与此同时乙发现…”。
- 计算当前剩余错误时,只减去“改正”的数量(通常是甲的)。乙虽然发现了,但如果题目没说乙改正了,就算作乙只是为了帮我们估算总数用的工具人,他的发现不影响当前的剩余错误数(除非题目明确说“甲和乙发现的都改正了”)。
- 笔记中的真题逻辑:通常默认是只减去甲改正的数量。
计算结果不是整数怎么办?
- 如果在第一步算 时算出了小数(比如 80.5),通常说明你算错了,或者是题目出得不好。但在后续步骤算出小数(比如需要再改 58.6 个错误),一定要向上取整(改 58 个达不到目标,必须改 59 个)。
UML 建模
根据笔记,主要考用例图、顺序图和类图。
- 用例图 (Use Case Diagram)
- 画什么:
- 小人 (Actor):参与者(用户、外部系统)。
- 椭圆 (Use Case):功能(动宾短语,如“借阅书籍”)。
- 连线:实线连接。
- 关系:
<<include>>(包含):A必然调用B(虚线箭头指向B)。<<extend>>(扩展):B在特定条件下扩展A(虚线箭头指向A)。
- 顺序图 (Sequence Diagram)
- 画什么:
- 方框:对象(如
:Customer,:System)。 - 虚线:生命线。
- 实心箭头:同步消息(调用方法)。
- 虚线箭头:返回消息。
- 长条矩形:激活期(表示正在处理)。
- 方框:对象(如
- 解题技巧:根据题目给出的“剧本”(如:顾客输入ID -> 系统验证 -> 返回结果),按时间顺序从上往下画箭头。
- 类图 (Class Diagram)
- 画什么:三层方框(类名、属性、方法)。
- 难点是关系(箭头):
- 关联:实线(A有一条线连B)。
- 泛化(继承):空心三角形实线(子类指父类)。
- 聚合:空心菱形(整体与部分,可分离,如:汽车和轮胎)。
- 组合:实心菱形(整体与部分,不可分,如:人和大脑)。
黑盒测试
等价类划分法:
题目会给你一个输入框的要求(比如:输入1到999之间的整数)。
你需要设计测试用例:
- 有效等价类:合法的(如 500)。
- 无效等价类:
- 小于范围(-1)。
- 大于范围(1000)。
- 类型不对(abc)。
- 为空(
null)。
答题格式:画表列出“输入数据”、“预期结果”、“覆盖的等价类编号”。
标星概念
概述
什么是软件
软件是计算机系统中与硬件相互依存的另一部分,它是包括程序、数据及其相关文档的完整集合。其中:
程序是按事先设计的功能和性能要求执行的指令序列;
数据是使程序能正常操纵信息的数据结构;
文档是与程序开发、维护和使用有关的图文材料。
软件的特点
- 软件是一种逻辑实体,而不是具体的物理实体,因而它具有抽象性;
- 软件的生产与硬件不同,在它的开发中没有明显的制造过程。对软件的质量控制,必须着重在软件开发方面下功夫
- 与硬件不同,软件在运行和使用期间,没有机械磨损、老化问题。
- 硬件磨损:可以用备用零件替换;
- 软件出故障:无法用备用零件替换来解决,是因为设计开发过程中存在错误;
- 软件维护比硬件维护更复杂,它与硬件的维修有本质差别:
软件危机
在程序系统阶段,软件技术的发展不能满足需要,“软件危机”就这样出现了。
软件危机是指:在计算机软件的开发和维护过程中所遇到的一系列严重问题。
几乎所有软件都不同程度地存在这些问题。
大体上,这些问题分为两方面:
如何开发软件,以满足对软件日益增长的需求;
如何维护数量不断膨胀的已有软件。
软件工程的定义
软件工程是指导计算机软件开发和维护的一门工程学科。采用工程的概念、原理、技术和方法来开发与维护软件,把经过时间考验而证明正确的管理技术和当前能够得到的最好的技术方法结合起来,以经济地开发出高质量的软件并有效地维护它,这就是软件工程。
软件工程的基本原理
著名的软件工程专家B.W.Boehm于1983年提出了软件工程的七条基本原理。他认为这七条原理是确保软
件产品质量和开发效率的原理的最小集合:
- 用分阶段的生命周期计划严格管理;
把软件生命周期划分成若干阶段,并相应制定出切实可行的计划,并严格按照计划对软件的开
发与维护工作进行管理; - 坚持进行阶段评审;
大部分错误是在编码之前造成的,例如,根据Boehm等人的统计,设计错误占软件错误的
63%,编码错误仅占37%;
错误发现与改正得越晚,所需付出的代价也越高。 - 实行严格的产品控制;
当改变需求时,为了保持软件各个配置成分的一致性,必须实行严格的产品控制,其中主要是
实行基准配置管理。
所谓基准配置又称为基线配置,它们是经过阶段评审后的软件配置成分(各个阶段产生的文档
或程序代码)。
基准配置管理也称为变动控制:一切有关修改软件的建议,特别是涉及到对基准配置的修改建
议,都必须按照严格的规程进行评审,获得批准以后才能实施修改。 - 采用现代程序设计技术;
实践表明,采用先进的技术既可提高软件开发和维护的效率,又可提高软件产品的质量。 - 结果应能清楚地审查;
为了提高软件开发过程的可见性,更好地进行管理,应该根据软件开发项目的总目标及完成期
限,规定开发组织的责任和产品标准,从而使得所得到的结果能够清楚地审查。 - 开发小组的成员应该少而精;
开发小组人员的素质和数量是影响软件产品质量和开发效率的重要因素。 - 承认不断改进软件工程实践的必要性。
不仅要积极主动地采纳新的软件技术,而且要注意不断总结经验,评价新的软件技术的效果,
指明必须着重开发的软件工具和应该优先研究的技术。
软件工程方法学
通常把在软件生命周期全过程中使用的一整套技术方法的集合称为方法学(methodology),也称为范型(paradigm)。
软件工程方法学包含三个要素:方法、工具和过程。
传统方法学
传统方法学又称生命周期方法学或结构化范型。
采用结构化技术(结构化分析、结构化设计和结构化实现)来完成软件开发的各项任务,并使用适当的软件工具或软件工程环境来支持结构化技术的运用。
把软件生命周期的全过程划分为若干个阶段:
前一阶段是基础、前提;后一阶段是细化;
每一个阶段的开始和结束都有严格的标准;
在每一个阶段结束之前都必须进行正式严格的技术审查和管理复审;
面向对象方法学
面向对象方法学是一种以数据为主线,把数据和对数据的操作紧密地结合起来的方法。
面向对象方法学的4个要点:“面向对象=对象+类+继承+通信”
- 把对象作为融合了数据及在数据上的操作行为的统一的软件构件;
- 把所有对象都划分成类;
- 按照父类与子类的关系,把若干个相关类组成一个类层次结构,位于下层的类继承了上层中某类的特点;
- 对象彼此间仅能通过发送消息互相联系。
面向对象方法学的出发点和基本原则,是尽量模拟人类习惯的思维方式,使开发软件的方法与过程尽可能接近人类认识世界解决问题的方法与过程,从而使描述问题的问题空间与实现解法的求解空间在结构上尽可能一致。
软件生命周期
它是一个从用户需求开始,经过开发、交付使用,在使用中不断增补修订,直至让位于新软件的全过程;
概括地说,软件生命周期由软件定义、软件开发和运行维护3个时期组成,每个时期又进一步划分成若干个阶段。
软件过程
软件过程是为了获得高质量软件所需要完成的一系列任务的框架,它规定了完成各项任务的工作步骤。
ISO 9000对过程的定义: 使用资源将输入转化为输出的活动所构成的系统。
瀑布模型
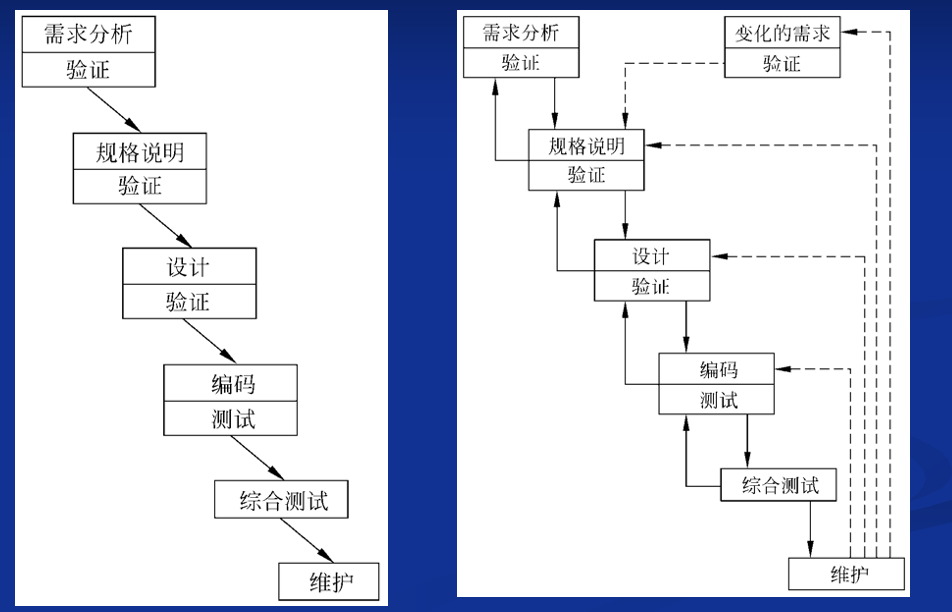
原型/快速原型模型
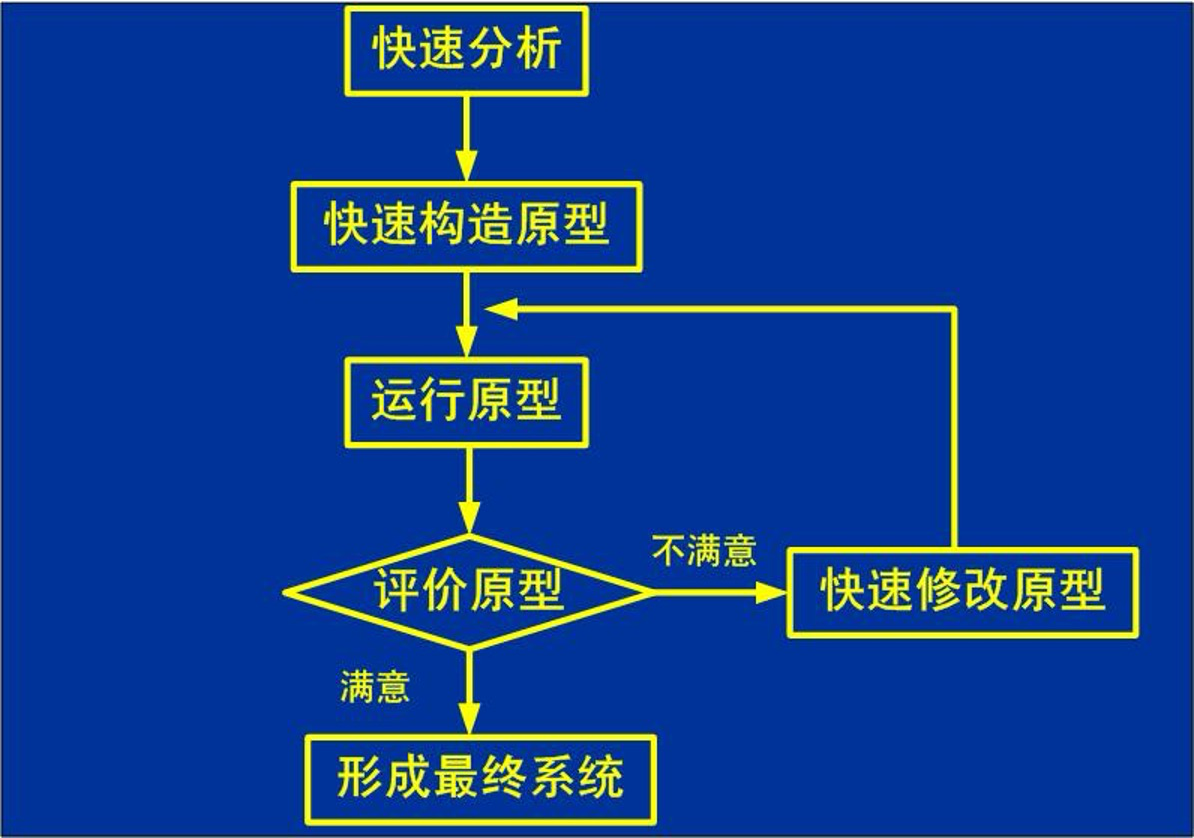
所谓原型,是一个可以实际运行的模型,它在功能上可以看作是最终产品的一个子集(展示了目标系统的关键功能)。
快速原型化的软件开发大体可以如下图所示:
阶段式开发(演化模型)
软件系统和其他所有复杂系统一样,是随着时间不断演化的。业务需求和产品需求随着开发向前推进经常发生改变,这使得直线式的开发模型不切实际。
来自时间、成本、人力以及技术等方面的压力往往使得演化成为软件开发的必经之路。
阶段式开发大体分为两种:
- 渐增式开发
- 迭代式开发(螺旋式开发)
螺旋模型
软件项目中的风险:
- 人员
- 硬件设备
- 项目的生存能力等
螺旋模型的基本思想是,使用原型及其他方法来尽量降低风险。理解这种模型的一个简便方法,是把它看作在每个阶段之前都增加了风险分析过程的快速原型模型
敏捷过程
敏捷过程的价值观
- 个体和交互胜过过程和工具
- 可以工作的软件胜过面面俱到的文档
- 客户合作胜过合同谈判
- 响应变化胜过遵循计划
敏捷过程的原则
- 我们最优先要做的是通过尽早的,持续的交付有价值的软件来使客户满意
- 即使到了开发的后期,也欢迎改变需求.敏捷过程利用变化来为客户创造竞争优势
- 经常性地交付可以工作的软件,交付的间隔可以从几周到几个月,交付的时间间隔越短越好
- 在整个项目开发期间,业务人员和开发人员必须天天都在一起工作
- 围绕被激励起来的个人来构建项目.给他们提供所需要的环境和支持,并且信任他们能够完成工作
- 在团队内部,最具有效果并且富有效率的传递信息的方法,就是面对面的交谈
- 工作的软件是首要的进度度量标准
- 敏捷过程提倡可持续的开发速度.责任人、开发者和用户应该能够保持一个长期的、恒定的开发速度
- 不断地关注优秀的技能和好的设计会增强敏捷能力
- 简单是根本的
- 最好的架构、需求和设计出自于自组织的团队
- 每隔一段时间,团队就会在如何才能更有效地工作方面进行反省,然后相应地对自己的行为进行调整
可行性研究
可行性研究的任务
可行性研究的目的:
- 用最小的代价,在尽可能短的时间内确定问题是否能够解决。
可行性研究的实质:
- 就是一次压缩、简化了的系统分析和设计的过程。
可行性研究应着重考虑如下几个方面:
- 技术可行性:使用现有的技术能否实现这个系统。
- 经济可行性:进行成本∕效益分析。从经济角度判断系统开发是否“合算”。
- 操作可行性:系统的操作方式在这个用户组织内是否行得通。
- 法律可行性:确定系统开发可能导致的任何侵权、妨碍和责任。
- 开发方案的选择性研究:提出并评价实现系统的各种开发方案,并推荐较优方案。
系统流程图
系统流程图是概括地描绘物理系统的传统工具。它的基本思想是用图形符号以黑盒子形式描绘组成系统的每个部件。包括程序、文档、数据库和人工过程等。它表达了数据在系统各部件之间的流动情况。

数据流图(DFD)

数据字典
数据字典是对数据流图中包含的所有元素的定义的集合,数据词典与数据流图共同构成系统的逻辑模型。
数据字典主要会定义下面四种类型:
- 数据流
- 数据流分量(即数据元素)
- 数据存储
- 处理
数据流是数据结构在系统内传播的路径。一个数据流词条应有以下几项内容:
数据流名:
说明:简要介绍作用即它产生的原因和结果;
数据流来源:来自何方;
数据流去向:去向何处;
数据流组成:数据结构;
每个数据量的流通量:数据量,流通量;
定义绝大多数复杂事物的方法,都是用被定义的事物的成分的某种组合表示这个事物,这些组成成分又由更低层的成分的组合来定义。
- 顺序 即以确定次序连接两个或多个分量
- 选择 即从两个或多个可能的元素中选取一个
- 重复 即把指定的分量重复零次或多次
- 可选 即一个分量是可有可无的(重复零次或一次)
需求分析
需求分析的任务
- 必须理解并描述问题的信息域,根据这条准则应该建立数据模型;
- 必须定义软件应完成的功能,这条准则要求建立功能模型;
- 必须描述作为外部事件结果的软件行为,这条准则要求建立行为模型;
- 必须对描述信息、功能和行为的模型进行分解,用层次的方式展示细节。
确定对系统的综合要求:
- 功能需求
- 性能需求
- 可靠性和可用性需求
- 出错处理需求
- 接口需求–用户接口需求;硬件接口需求;软件接口需求;通信接口需求
- 约束–精度;工具和语言约束;设计约束;应该使用的标准;应该使用的硬件平台
- 逆向需求
- 将来可能提出的要求
分析系统的数据要求
- 建立数据模型
- E-R图
- 复杂数据结构的描述 :
- 数据字典
- 层次方框图
- Warnier图
- 数据库
- 数据规范化
导出系统的逻辑模型
- 软件系统详细的逻辑模型通常用数据流图、实体-联系图、状态转换图、数据字典和主要的处理算法描述
修正系统的开发计划
- 可以比较准确地估计系统的成本和进度,修正以前制定的开发计划。
与用户沟通获取需求的方法
- 访谈
- 面向数据流自顶向下求精
- 简易的应用规格说明技术
- 快速建立软件原型
状态转换图
状态转换图(简称为状态图)通过描绘系统的状态及引起系统状态转换的事件,来表示系统的行为。
状态:状态是任何可以被观察到的系统行为模式,规定了系统对事件的响应方式
事件:在某个特定时刻发生的事情,它是对引起系统做动作或(和)从一个状态转换到另一个状态的外界事件的抽象
验证软件需求
从哪些方面验证软件需求的正确性
- 一致性
- 完整性
- 现实性
- 有效性
总体设计
软件设计过程
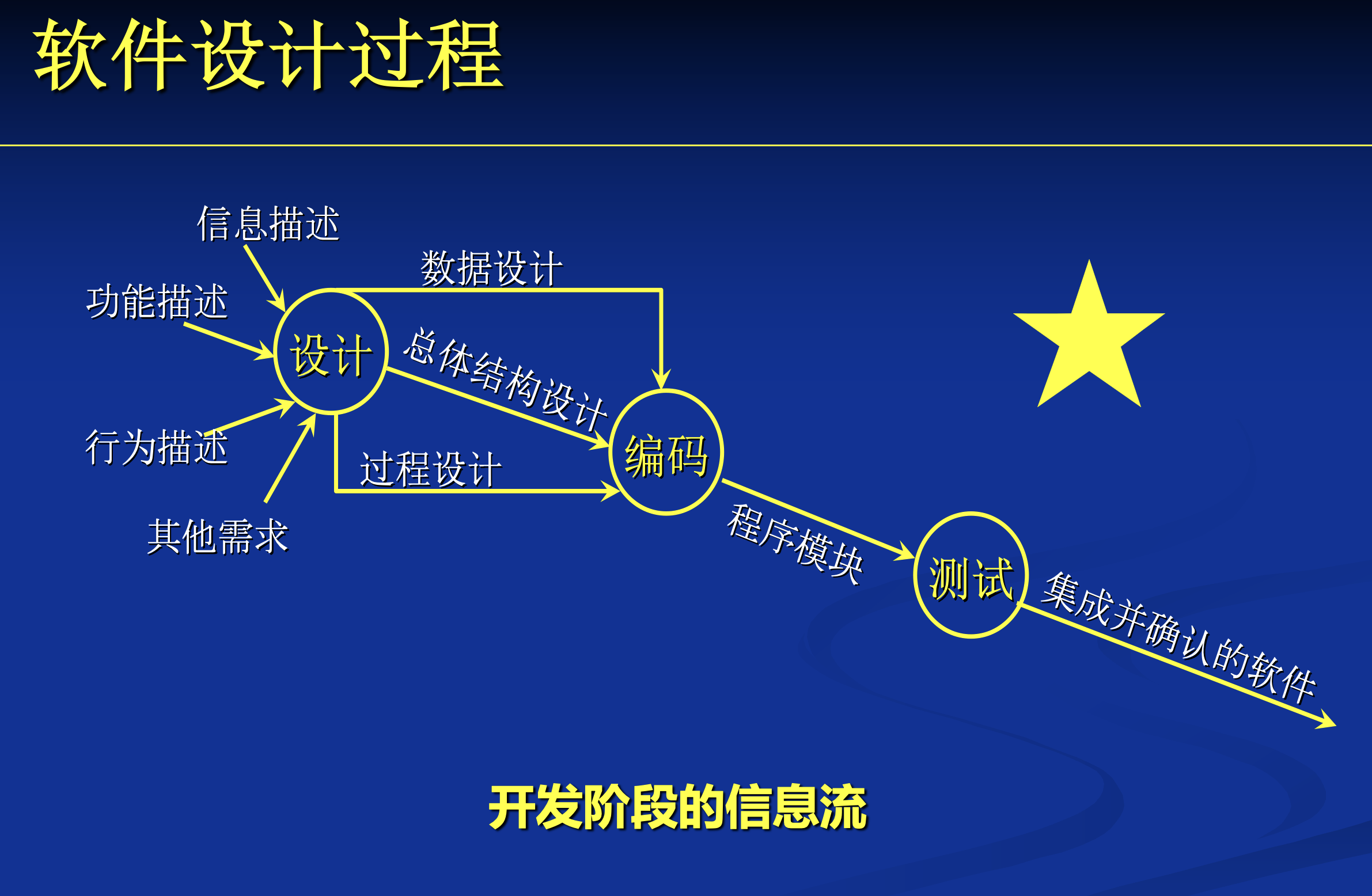
概要设计/总体设计:将软件需求转化为数据结构和软件的系统结构,即系统的模块划分。
详细设计:通过对系统的结构表示(每个模块的内部工作)进行细化,得到软件的详细的数据结构和算法。
软件设计的原理
模块化
模块:可单独命名和可编址的部分。(另:由边界元素限定的相邻程序元素的序列,而且有一个总体标识符代表它)如:procedure, function, subroutine, block,Macro
模块化:程序划分成独立命名且可独立访问的模块,每个模块完成一个子功能,把这些模块集成起来构成一个整体,可以完成指定的功能满足用户的需求。
模块化的根据:
设函数C(X)定义问题X的复杂程度,
且函数E(X)确定解决问题X需要的工作量(时间),
对于两个问题P1和P2,如果:C(P1)>C(P2),
显然:E(P1)>E(P2);
根据人类解决一般问题的经验,另一个有趣的规律是:
C(P1 + P2)>C(P1)+C(P2),
由此不难得出:
E(P1 + P2)>E(P1)+E(P2)。
模块并非越多越好:
- 随着模块数目增加,设计模块间接口所需要的工作量也将增加。
模块化原理的好处:
- 软件结构清晰 ,容易设计、阅读和理解;
- 软件容易测试和调试,因而有助于提高软件的可靠性;
- 能够提高软件的可修改性;
- 有助于软件开发工程的组织管理;
抽象
抽象:抽出事物的本质特性而暂时不考虑它们的细节。
软件设计过程应当是在不同抽象级别考虑和处理问题的过程。
软件工程过程的每一步都是对软件解法的抽象层次的一次精化。
- 过程抽象:把完成一个特定功能的动作序列抽象为一个过程名和参数表,以后通过指定过程名和实际参数调用此过程。
- 数据抽象:把一个数据对象的定义抽象为一个数据类型名,用此类型名可定义多个具有相同性质的数据对象。
逐步求精
可以把逐步求精定义为:“为了能集中精力解决主要问题而尽量推迟对问题细节的考虑。”
人类的认知过程遵守Miller法则:一个人在任何时候都只能把注意力集中在(7±2)个知识块上。
逐步求精可视为一种自顶向下的设计策略。按照这种设计策略,程序的体系结构是通过逐步精化处理过程的层次而设计出来的。通过逐步分解对功能的宏观陈述而开发出层次结构,直至最终得出用程序设计语言表达的程序。
信息隐藏和局部化
对于如何分解软件,信息隐藏原理指出:模块应该设计成其中包含的信息(过程和数据)对不需要这些信息的其他模块来说是不可访问的。
局部化:指把一些关系密切的软件元素物理地放得彼此靠近 。
隐藏的是模块的实现细节。
好处:
支持模块的并行开发;
使得软件易修改,减少后期测试和维护的工作量;
系统易于扩充。
模块独立性
模块独立:每个模块完成一个相对独立的子功能,并且和其他模块之间的关系很简单。
它是模块化、抽象、信息隐藏和局部化概念的直接结果。
模块独立的理由:
- 第一,有效的模块化(即具有独立性的模块)的软件比较容易开发出来;
- 第二,独立的模块比较容易测试和维护。
模块的独立程度可以由两个定性标准度量,这两个标准分别称为耦合和内聚。
耦合(Coupling):衡量不同模块彼此间互相依赖(连接)的紧密程度;
内聚(Cohesio):衡量一个模块内部各个元素彼此结合的紧密程度。
耦合
耦合是对一个软件结构内不同模块之间互连程度的度量。耦合强弱取决于模块间接口的复杂程度,进入或访问一个模块的点,以及通过接口的数据。在软件设计中应该追求尽可能松散耦合的系统。
模块间的耦合程度强烈影响系统的可理解性、可测试性、可靠性和可维护性。
耦合(Coupling)是模块与其他模块、外界之间连接程度的量化指标,模块间联系越紧密、越多,耦合度就越高,模块的独立性就越差。
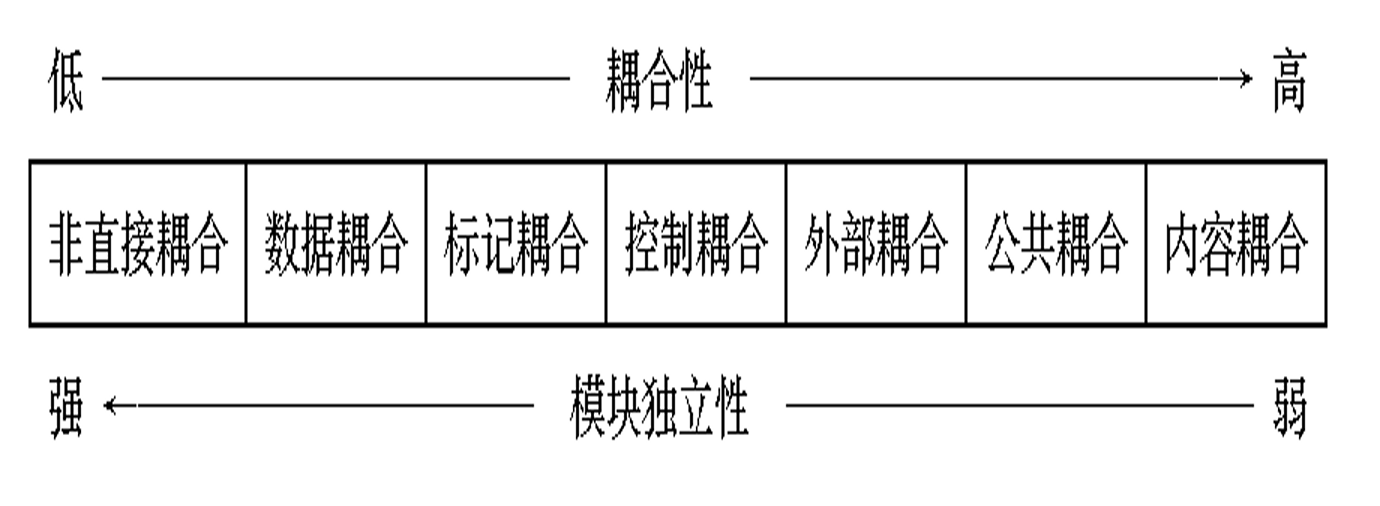
非直接耦合(Nondirect Coupling):无直接联系
数据耦合(Data Coupling):低耦合
- 一个模块访问另一个模块时,彼此之间是通过简单数据参数 (不是控制参数、公共数据结构或外部变量) 来交换输入、输出信息的
标记耦合(Stamp Coupling):能化为数据耦合
- 一组模块通过参数表传递记录信息,就是标记耦合。这个记录是某一数据结构,而不是简单变量
- 标记耦合使在数据结构上的操作复杂化了,把在数据结构上的操作全部集中在一个模块中,可消除或转化这种耦合
控制耦合(Control Coupling):中等耦合度,如果一个模块通过传送开关、标志、名字等控制信息,明显地控制选择另一模块的功能,就是控制耦合
- 这种耦合实质是在单一接口上选择多功能模块中的某项功能
- 控制耦合意味着A必须知道B内部的一些逻辑关系,这会降低模块的独立性
外部耦合(External Coupling):若不可避免,尽量集中
- 一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息,则称之为外部耦合
- 例如C语言程序中有模块访问被修饰为
extern的外部变量 - 外部耦合会引起下列问题:
- 无法控制各模块对公共数据的存取,严重影响软件模块的可靠性和适应性
- 公共数据名的使用,明显降低了程序的可读性
公共耦合(Common Coupling):危险,慎用
- 若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为公共耦合。公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。
- 例如:FORTRAN语言中的
COMMO区可以使访问它的模块间发生公共耦合 - 这种耦合会引起下列问题:
- 所有公共耦合模块都与某个公共数据环境内部各项的物理安排有关,若修改某个数据的大小,将会影响到所有模块
- 无法控制各模块对公共数据的存取,严重影响软件模块的可靠性和适应性
- 公共数据名的使用,明显降低了程序的可读性
内容耦合(Content Coupling):耦合度最高,现代高级语言基本上不允许出现内容耦合
- 如果发生下列情形,两个模块之间就发生了内容耦合
- 一个模块直接访问另一个模块的内部数据
- 一个模块不通过正常入口转到另一模块内部
- 两个模块有一部分程序代码重迭(只可能出现在汇编语言中)
- 一个模块有多个入口
- 如果发生下列情形,两个模块之间就发生了内容耦合
针对耦合的设计指导原则:
尽量使用数据耦合;
少用控制耦合和特征耦合;
限制外部耦合和公共耦合;
完全不用内容耦合。
降低耦合度的方法:
- 根据问题的特点,选择适当的耦合类型;(控制耦合?出错处理?)
- 降低模块接口的复杂性;(信息数量/通信方式/信息结构)
- 把模块的通信信息放在缓冲区中;
内聚
内聚(Cohesio)标志一个模块内各个元素彼此结合的紧密程度,是模块功能强度的度量,用来量化表示一个模块在多大程度上专注于一件事情 。一个模块内部各个元素彼此结合得越紧密,内聚度就越高,模块独立性就越强
偶然内聚(Coincidental Cohesio)
- 当模块内各部分之间没有联系,或者即使有联系,这种联系也很松散,则称这种模块为偶然内聚模块,它是内聚程度最低的模块
- 例如,一些没有任何联系的语句可能在许多模块中重复出现多次,程序员为节省存储,把它们抽出来组成一个新的模块,这样的就是偶然内聚模块。
- 这种模块存在的问题:
- 不易修改和维护
- 其内容不易理解
- 可能会把一个完整的程序段分割到许多模块内,在程序中频繁互相调用
逻辑内聚(Logical Cohesio):逻辑组合关系是千变万化的
- 这种模块把几种相关的功能组合在一起,每次调用时,由传送给模块的判定参数来确定该模块应执行哪一种功能;
- 是单接口多功能模块,类似的有错误处理模块,接收错误代码,做出不同的响应。
- 这种模块存在的问题:
- 不是执行一种功能,而是若干功能中的一种,因此它不易修改;
- 调用它时要传递控制参数,形成控制耦合;
- 将未用的部分也调入内存,降低系统效率;
时间内聚(Classical Cohesio)
- 这种模块大多为多功能模块,但模块的各个功能的执行与时间有关,通常要求所有功能必须在同一时间段内执行,例如初始化模块和终止模块
- 时间内聚比逻辑内聚强一些,因为时间内聚模块中各个部分都要在同一个时间段内执行,而且一般情形下,各部分可以按顺序执行,所以其内部存在的逻辑判定转移更少,但要注意时序问题
过程内聚(Procedural Cohesio):“程序流程图的一部分”
- 使用流程图做为工具设计程序时,把流程图中的某一按顺序执行的部分划出组成模块,就得到过程内聚模块。
- 过程内聚模块仅包含完整功能的一部分,所以它的内聚度仍较低,造成的模块间的耦合度还是较高
通信内聚(Communicational Cohesio):数据是联系的纽带
- 如果一个模块内各功能部分都使用了相同的输入数据,或产生了相同的输出数据(围绕着同一堆数据进行工作),则称之为通信内聚模块。通常,通信内聚模块是通过数据流图来定义的
- 因为是操作或生成同一个数据集,所以内聚度较高,但可能破坏功能独立性
顺序内聚(Sequential Cohesio):接近单一
- 一个模块内的处理元素和同一个功能密切相关,而且这些处理必须顺序执行,通常一个处理元素的输出数据作为下一个处理元素的输入数据
- 根据数据流图划分模块时,通常得到顺序内聚的模块。
功能内聚(Functional Cohesio):只做一件事
- 一个模块中各个部分都是完成某一具体功能必不可少的组成部分,或者说该模块中所有部分都是为了完成一项具体功能而协同工作,紧密联系,不可分割的。则称该模块为功能内聚模块。
- 这种模块易于修改和维护,因为它们的功能是明确的,模块间的耦合是简单的。
启发规则
改进软件结构提高模块独立性:
- 设计出软件的初步结构以后,应该审查分析这个结构,通过模块分解或合并,力求降低耦合提高内聚。
- 模块功能的完善化(一个完整的功能模块,不仅能够完成指定的功能,还应能告诉使用者完成任务的状态):
- 执行规定的功能的部分;
- 出错处理部分;
- 如需要返回一系列数据给调用者,在完成数据加工或结束时应告诉调用者完成任务的状态(即返回一个该模块是否正确结束的标志)。
- 消除重复功能,改善软件结构:
模块规模应该适中:
过大的模块可理解性差。W.M.Weinberg的研究表明:当模块长度超过30条语句时,其可理解性将迅速下降。F.T.Baker建议:模块长度可选在50句左右,使之能打印在一张打印纸上,免得读程序时要来回翻页
过大的模块往往是由于分解不充分,可以对功能进一步分解,生成一些下级模块或同层模块;分解模块不应该降低模块的独立性。
过小的模块开销大于有效操作,而且模块数目过多使系统接口复杂。
深度、宽度、扇出和扇入都应适当:
- 深度(depth):表示软件结构中控制的层数,它往往能粗略地标志一个系统的大小和复杂程度。
- 宽度(width):是软件结构内同一个层次上的模块总数的最大值。一般说来,宽度越大系统越复杂。
- 扇出(fan-out):是一个模块直接控制(调用)的模块数目,扇出过大意味着模块过分复杂,需要控制和协调过多的下级模块;扇出过小(例如总是1)也不好。经验表明,一个设计得好的典型系统的平均扇出通常是3或4(扇出的上限通常是5~9)。
- 扇入(fan-in):表明有多少个上级模块直接调用它。
- 避免“扁平结构”,追求“椭圆结构”
模块的作用域应该在控制域之内 :
- 模块的作用域:定义为受该模块内一个判定影响的所有模块的集合。
- 模块的控制域:是这个模块本身以及所有直接或间接从属于它的模块的集合。
- 在一个设计得很好的系统中,所有受判定影响的模块应该都从属于做出判定的那个模块,最好局限于做出判定的那个模块本身及它的直属下级模块。
- 将作用范围移动到控制范围的方法:
- 将判定所在模块合并到父模块中,使判定处于较高层次;
- 将受判定影响的模块下移到控制范围内;
- 将判定上移到层次中较高的位置。
力争降低模块接口的复杂程度:
- 模块接口复杂是软件发生错误的一个主要原因。应该仔细设计模块接口,使得信息传递简单并且和模块的功能一致
1 | |
设计单入口单出口的模块:
- 避免出现内容耦合。
模块功能应该可以预测 ,避免对模块施加过多限制:
- 如果一个模块可以当做一个黑盒子,也就是说, 只要输入的数据相同就产生同样的输出,这个模块的功能就是可以预测的。
面向数据流的设计方法
通常所说的结构化设计方法(简称SD方法),也就是基于数据流的设计方法。面向数据流的设计方法把信息流映射成软件结构,信息流的类型决定了映射的方法。信息流可以分为变换流和事务流:
- 变换流:信息沿输入通路进入系统,同时由外部形式变换成内部形式,进入系统的信息通过变换中心,经加工处理以后再沿输出通路变换成外部形式离开软件系统。当数据流图具有这些特征时,这种信息流就叫作变换流。
- 变换型数据处理问题的工作过程大致分为三步,即取得数据,变换数据和给出数据。
- 相应于取得数据、变换数据、给出数据,变换型系统结构图由输入、变换中心和输出等三部分组成。
- 事务流:数据沿输入通路到达一个处理 ,这个处理根据输入数据的类型在若干个动作序列中选出一个来执行。这类信息流被称为事务流,而该处理 称为事务中心,它完成下述任务:
- 接收输入数据(输入数据又称为事务transaction);
- 分析每个事务以确定它的类型;
- 根据事务类型选取一条活动通路。
面向数据流的设计方法的基本过程:
- 研究、分析和审查数据流图;
- 根据数据流图决定问题的类型;
- 由数据流图推导出系统的初始结构图;
- 根据启发规则对结构进行细化;
- 修改和补充数据字典;
- 制定测试计划。
变换分析
变换分析:把具有变换流特点的数据流图按预先确定的模式映射成软件结构的一系列步骤的总称。
复查基本系统模型。
- 复查的目的是确保系统的输入数据和输出数据符合实际。
复查并精化数据流图。
- 对需求分析阶段得出的数据流图认真复查,并且在必要时进行精化;
- 确保数据流图给出了目标系统的正确的逻辑模型;
- 使数据流图中每个处理都代表一个规模适中相对独立的子功能。
确定数据流图具有变换特性还是事务特性。
- 根据数据流图中占优势的属性,确定数据流的全局特性。
- 注意把和全局特性有不同特点的局部区域孤立出来,为以后精化软件结构做准备。
确定输入流和输出流的边界,从而孤立出变换中心。
完成“第一级分解(first level factoring)”。
- 分解就是分配控制的过程。
- 分解出模块:Cm,Ca,Ct,Ce,其中:
- Cm:协调下述从属的控制功能;
- Ca:输入信息处理控制模块,协调对所有输入数据的接收;
- Ct:变换中心控制模块,管理对内部形式的数据的所有操作;
- Ce:输出信息处理控制模块,协调输出信息的产生过程。
完成“第二级分解”。
- 即把数据流图中的每个处理映射成软件结构中一个适当的模块。
- 方法是,从变换中心的边界开始沿着输入通路向外移动,把输入通路中每个处理映射成软件结构中Ca控制下的一个低层模块;
- 然后沿输出通路向外移动,把输出通路中每个处理映射成直接或间接受模块Ce控制的一个低层模块;
- 最后把变换中心内的每个处理映射成受Ct控制的一个模块。
- 为每个模块写一个简要说明:
- 进出该模块的信息(接口描述);
- 模块内部的信息;
- 过程陈述,包括主要判定点及任务等;
- 对约束和特殊特点的简短讨论。
- 即把数据流图中的每个处理映射成软件结构中一个适当的模块。
使用设计度量和启发式规则对第一次分割得到的软件结构进一步精化。
- 第一次分割得到的软件结构,总可以根据模块独立原理进行精化。
- 为获得尽可能高的内聚、尽可能松散的耦合,应该对初步分割得到的模块进行再分解或合并。
上述7个步骤的目的是开发出软件的整体表示。这种整体表示的意义在于:
- 一旦确定了软件结构就可以把它作为一个整体来复查,从而能够评价和精化软件结构;
在这个时期进行修改只需要很少的附加工作,但却能够对软件的质量特别是软件的可维护性产生深远的影响。
软件体系结构
软件体系结构是对子系统、软件系统构件以及它们之间相互关系的描述。
子系统和构件一般定义在不同的视图内,以显示软件系统的相关功能属性和非功能属性。
系统的软件体系结构是一种软件设计活动的工作产品。
软件体系结构风格
软件体系结构风格根据软件系统的结构定义了软件系统族。它通过施加于构件上的限制及组成与设计规则来表现构件和构件间的关系。体系结构风格为一个软件系统及怎样建造该系统的相关方法表示了一种特殊的基本结构。
Garla和Shaw对通用体系结构风格的分类:
- 数据流风格:批处理序列;管道/过滤器;
- 调用/返回风格:主程序/子程序;面向对象风格;层次结构;
- 独立构件风格:进程通讯;事件系统;
- 虚拟机风格:解释器;基于规则的系统;
- 仓库风格:数据库系统;黑板系统;
每种体系结构风格定义了:
- 一组构件:完成系统所需的某种功能;
- 一组连接件:实现构件间的“通信、协调和合作”;
- 约束:定义构件如何被集成到一起形成系统;
- 语义模型:使得设计者能够通过分析系统的构成成分的已知性质而理解系统的整体性质。
管道/过滤器风格
每个构件都有一组输入和输出,构件读输入的数据流,经过内部处理,然后产生输出数据流。这个过程通常通过对输入流的变换及增量计算来完成,所以在输入被完全消费之前,输出便产生了。因此,这里的构件被称为过滤器(Filters)。
连接件就象是数据流传输的管道(Pipes),将一个过滤器的输出传到另一过滤器的输入
该风格的限制条件:
过滤器必须是独立的实体,它不能与其它的过滤器共享状态;
一个过滤器不知道它上游和下游的标识;
一个管道/过滤器网络输出的正确性不应依赖于过滤器进行增量计算过程的顺序。
该风格的特例:
pipelines:将拓扑结构限定为过滤器的线性结构。
bounded pipes:限定了可以存在于一个管道上的数据量。
typed pipes:在两个过滤器之间传递的数据具有特定的类型。
batch sequential:每个过滤器把它所有的输入作为一个单一实体进行处理。
应用:
Unix shell
编译器
管道/过滤器风格的优点:
使得软构件具有良好的隐蔽性和高内聚、低耦合的特点;
允许设计者将整个系统的输入/输出行为看成是多个过滤器的行为的简单合成;
支持软件重用。只要提供适合在两个过滤器之间传送的数据,任何两个过滤器都可被连接起来;
易于维护和增强系统。新的过滤器可以添加到现有系统中来;旧的可以被改进的过滤器替换掉;
允许对一些如吞吐量、死锁等性质的分析;
支持并行执行。每个过滤器是作为一个单独的任务完成,因此可与其它任务并行执行。
管道-过滤器风格的缺点:
通常导致进程成为批处理的结构。这是因为虽然过滤器可增量地处理数据,但它们是独立的,所以设计者必须将每个过滤器看成一个完整的从输入到输出的转换。
不适合处理交互的应用。当需要增量地显示改变时,这个问题尤为严重。
因为在数据传输上没有通用的标准,每个过滤器都增加了解析和合成数据的工作,这样就导致了系统性能下降,并增加了编写过滤器的复杂性。
数据抽象与面向对象风格
将数据的表示和相关操作封装在一个抽象数据类型或对象中。这种风格的构件是对象,或者说是抽象数据类型的实例。对象是通过函数和过程的调用来交互的。
该风格的两个限制:
对象要负责保证其数据表示的完整性;
对象的数据表示对其他对象来说是隐藏的。
面向对象风格的优点:
- 因为对象对其它对象隐藏它的表示,所以可以改变一个对象的表示,而不影响其使用者。
- 由于访问数据的操作和数据的绑定使得设计者可将问题分解成一些交互的代理程序的集合。
面向对象风格的缺点:
- 为了使一个对象和另一个对象通过过程调用等进行交互,必须知道对象的标识。只要一个对象的标识改变了,就必须修改所有其他明确调用它的对象。
- 必须修改所有显式调用它的其它对象,并消除由此带来的一些副作用。例如,如果A使用了对象B,C也使用了对象B,那么,C对B的使用所造成的对A的影响可能是料想不到的。
基于事件/隐式调用风格
基于事件的隐式调用(Implicit Invocatio)风格的思想是构件不直接调用一个过程,而是发布或广播一个或多个事件。系统中的其它构件为它感兴趣的事件注册过程。
当一个事件被发布,系统自动调用在这个事件中注册的所有过程,这样,一个事件的发布就“隐式地”激发了另一模块中的过程。
从体系结构上说,这种风格的构件是一些模块,这些模块的接口既提供了一些过程,也有一些事件的集合。过程可以用通用的方式调用,构件也可以在系统事件中注册一些过程,当发生这些事件时,过程被调用。
该风格的特点:
- 事件的发布者并不知道哪些构件会被这些事件影响。这样不能假定构件的处理顺序,甚至不知道哪些过程会被调用。
应用:
在编程环境中用于集成各种工具;
在数据库管理系统中确保数据的一致性约束;
在用户界面系统中管理数据;
以及在编辑器中支持语法检查。
例如在某系统中,编辑器和变量监视器可以登记(注册)相应Debugger的断点事件。当Debugger在断点处停下时,它声明该事件,由系统自动调用对该事件感兴趣的处理程序,如编辑程序可以卷屏到断点,变量监视器刷新变量数值。而Debugger本身只声明事件,不关心这些过程做什么处理。
隐式调用风格的优点:
为软件重用提供了强大的支持。当需要将一个构件加入现存系统中时,只需将它注册到系统的事件中。
为改进系统带来了方便。当用一个构件代替另一个构件时,不会影响到其它构件的接口。
缺点:
构件放弃了对系统计算的控制。事件的发布者并不直接控制事件触发后的行为,因此无法预测哪些过程会被调用,以及它们会按什么顺序执行。
数据交换的问题。事件驱动机制需要通过事件传递数据,如何确保数据一致性和正确性需要额外的管理和设计。
既然过程的语义必须依赖于被触发事件的上下文约束,关于正确性的推理存在问题。由于事件的顺序和触发是隐式的,分析系统的行为和推理过程的正确性变得更加困难。
层次系统风格
层次系统(Layerd System)组织成一个层次结构,每一层为上层服务,并作为下层的客户。在一些层次系统中,除了一些精心挑选的用于输出的函数外,内部的层只对相邻的外层可见。
- 连接件由决定层间如何交互的协议来定义。
- 拓扑约束是对相邻层间交互的约束。
应用例子:分层通信协议、数据库系统、操作系统……
层次系统风格的优点:
支持基于抽象程度递增的系统设计;每一层抽象出不同的功能,具有较高的内聚性。这样,系统可以逐层进行设计和实现,增强了系统的可维护性和扩展性。
支持功能增强;通过添加新层,可以逐步增强系统的功能,而不会影响其他层的实现。例如,可以在协议栈中添加加密层,而不需要改变底层的传输协议。
支持重用。每个层次可以独立开发和测试,重用现有的层次和功能更加容易。
层次系统风格的缺点:
并不是每个系统都可以很容易地划分为分层的模式;并非所有系统都可以有效地划分为层次结构,特别是对于一些高度交互的系统,层次结构可能会显得过于简化。
很难找到一个合适的、正确的层次抽象方法。如何合理划分系统的层次以及定义每层的职责是一个复杂的问题,不当的设计可能导致系统复杂度的增加。
仓库风格
两种不同的构件:
中央数据结构说明当前状态;
一组独立构件在中央数据存贮上执行。
仓库风格使用一个中央数据结构(称为仓库)来管理系统的状态,而系统中的多个组件通过访问这个仓库来执行任务。仓库通常作为共享的数据存储,参与者(知识源)通过修改仓库中的数据来实现任务。
两个主要的子类别:
若是输入流中的事务类型触发选择执行进程的,则仓库是传统型数据库;
若是中央数据结构的当前状态触发选择执行进程的,则仓库是黑板系统。
黑板系统主要由三部分组成:
知识源:知识源中包含独立的、与应用程序相关的知识,知识源之间不直接进行通讯,它们之间的交互只通过黑板来完成。
黑板数据结构:黑板数据是按照与应用程序相关的层次来组织的问题求解状态数据,知识源通过不断地改变黑板数据来解决问题。
控制:控制完全由黑板的状态驱动,黑板状态发生改变知识源就会响应。
应用:
- 语音和模式识别系统
解释器风格
解释器风格通过将输入的伪代码或源代码转化为可以执行的实际代码。解释器通常将高级编程语言的源代码转化为机器代码或中间表示,并进行模拟执行。
解释器由四个部分组成:
用于存储待解释伪代码的内存;
用于转换伪代码并模拟其所代表的程序的解释引擎;
解释引擎的当前状态;
被模拟程序的当前状态。
过程控制风格
特点:
- 过程控制系统不仅是由在设计中出现的组件类型,而且由组件之间的关系刻画它的特征。
- 通过对输入和中间产品的持续的操作而将输入转换为具有特定属性的最终产品。
目的:
- 将过程结果的特定属性维持在称为“设定点”的参考值附近。(如:核电站/空调)
两种类型:
- 反馈控制系统
- 反馈控制系统测量一个受控变量,比如温度,并相应地调整过程,以保持受控变量接近或达到
设定点。 - 反馈控制原理:
根据对受控变量的度量来调整过程。
- 反馈控制系统测量一个受控变量,比如温度,并相应地调整过程,以保持受控变量接近或达到
- 前馈控制系统
- 在前馈控制中,系统通过测量其他可能是良好指标的过程变量,尝试预测对受控变量的未来影
响。 - 前馈控制原理:
测量其他的过程变量,根据它们的值来调整过程。
- 在前馈控制中,系统通过测量其他可能是良好指标的过程变量,尝试预测对受控变量的未来影
过程变量:某个过程的可以被测量的属性;
受控变量:系统希望控制其值变化的那些过程变量;
输入变量:用于监测过程的某个输入的过程变量;
操作变量: 控制器可改变其值的那些过程变量;
设置点(Set point):受控变量的期望值。
优点:
- 使受控变量的改变更加及时。
在设计过程控制系统时需要解决的问题:
- 需要监测哪些变量;
- 使用哪些传感器;
- 如何校准它们;
- 如何处理感知和控制的时间安排。
主要构件:
- 过程定义、过程变量、传感器、设定点、控制算法。
客户/服务器
客户系统请求某个动作或服务,服务器系统响应该请求。
服务器不必知道客户身份和数目;客户知道服务器的身份。
基于资源不对等,为实现共享而提出。
三层C/S结构风格
传统的二层C/S结构的局限:
- 单一服务器且以局域网为中心,难以扩展至大型企业广域网Internet。
- 软、硬件的组合及集成能力有限。
- 客户端的负荷太重,系统性能容易变坏。
- 数据安全性不好。
详细设计
结构程序设计
结构程序设计的经典定义如下所述:“如果一个程序的代码块仅仅通过顺序、选择和循环这3种基本控制结构进行连接,并且每个代码块只有一个入口和一个出口,则称这个程序是结构化的。”
对经典定义的扩充“结构程序设计是尽可能少用GOTO语句的程序设计方法。最好仅在检测出错误时才使用GOTO语句,而且应该总是使用前向GOTO语句。”
经典的结构程序设计:如果只允许使用顺序、IF-THEN-ELSE型分支和DO-WHILE型循环这3种基本控制结构实现单入口单出口的程序
扩展的结构程序设计:如果除了上述3种基本控制结构之外,还允许使用DO-CASE型多分支结构和DO-UNTIL型循环结构
修正的结构程序设计:如果再加上允许使用LEAVE(或BREAK)结构
过程设计技术和工具
表达过程规格说明的工具叫做详细设计工具:
图形工具
表格工具
语言工具
程序流程图(Program Flow Chart)
程序流程图本质上不是逐步求精的好工具,它诱使程序员过早地考虑程序的控制流程,而不去考虑程序的全局结构。
程序流程图中用箭头代表控制流,因此程序员不受任何约束,可以完全不顾结构程序设计的精神,随意转移控制。
程序流程图不易表示数据结构。
必须限制程序流程图只能使用五种基本的控制结构
需要对流程图所用的符号做出确切的规定
盒图(Box-Diagram)(N-S图)
盒图有下述特点:
- 功能域(即某个特定控制结构的作用域)明确,可以从盒图上一眼就看出来。
- 不可能任意转移控制。
- 很容易确定局部和全程数据的作用域。
- 很容易表现嵌套关系,也可以表示模块的层次结构。
PAD(Problem Analysis Diagram)图
用二维树形结构的图来表示程序的控制流, 设置了五种基本控制结构的图式,并允许递归使用。
PAD图的主要优点:
使用表示结构化控制结构的PAD符号所设计出来的程序必然是结构化程序
PAD图所描绘的程序结构十分清晰
用PAD图表现程序逻辑,易读、易懂、易记
容易将PAD图转换成高级语言源程序,这种转换可用软件工具自动完成
既可用于表示程序逻辑,也可用于描绘数据结构
PAD图的符号支持自顶向下、逐步求精方法的使用
判定表
当算法中包含多重嵌套的条件选择时,使用判定表能够清晰地表示复杂的条件组合与应做的动作之间的对应关系,判定表用于表示程序的静态逻辑。
在判定表中的条件部分给出所有的两分支判断的列表,动作部分给出相应的处理。
要求将程序流程图中的多分支判断都改成两分支判断。
优点:能够简洁、无二义性地描述所有的处理规则。
缺点:判定表表示的是静态逻辑,是在某种条件取值组合情况下可能的结果,它不能表达加工的顺序,也不能表达循环结构,因此判定表不能成为一种通用的设计工具。
判定树
判定树是判定表的变种。
优点:形式简单,比判定表更直观
缺点:
简洁性不如判定表
画判定树时分枝的次序可能对最终画出的判定树的简洁程度有较大影响
过程设计语言(PDL)
是用正文形式表示数据和处理过程的设计工具,也被称为伪代码。
PDL具有严格的关键字外部语法,用于定义控制结构和数据结构;另一方面,PDL表示实际操作和条件的内部语法通常又是灵活自由的,可以适应各种工程项目的需要。
PDL作为一种设计工具有如下一些优点:
- 可以作为注释直接插在源程序中间。这样做能促使维护人员在修改程序代码的同时也相应地修改PDL注释,因此有助于保持文档和程序的一致性,提高了文档的质量
- 可以使用普通的正文编辑程序或文字处理系统,很方便地完成PDL的书写和编辑工作。
- 已经有自动处理程序存在,而且可以自动由PDL生成程序代码。
PDL的缺点是不如图形工具形象直观,描述复杂的条件组合与动作间的对应关系时,不如判定表清晰简单。
McCabe 方法
McCabe方法根据程序控制流的复杂程度定量度量程序的复杂程度,这样度量出的结果称为程序的环形复杂度。
流图(也称为程序图):实质上是“退化了的”程序流程图,它仅仅描绘程序的控制流程,完全不表现对数据的具体操作以及分支或循环的具体条件。
结点:用圆表示,代表一条或多条语句;
边:用箭头表示,一边必须终止于一个结点;
区域:由边和结点围成的面积 ;
实现
编码风格
好程序的代码逻辑简明清晰、易读易懂:
程序的内部文档
数据说明
语句构造
输入/输出方法
效率问题
程序的内部文档
- 标识符的命名:
- 标识符即符号名,包括模块名、变量名、常量名、标号名、子程序名、数据区名以及缓冲区名等。这些名字应能反映它所代表的实际东西,应有一定实际意义。(例如,表示次数的量用Times,表示总量的用Total,表示平均值的用Average,表示和的量用Sum等。)
- 名字不是越长越好,应当选择精炼的意义明确的名字。
- 必要时可使用缩写名字,但这时要注意缩写规则要一致,并且要给每一个名字加注释。
- 在一个程序中,一个变量只应用于一种用途。
- 程序的注解:
- 夹在程序中的注释是程序员与日后的程序读者之间通信的重要手段。
- 注释决不是可有可无的。
- 一些正规的程序文本中,注释行的数量占到整个源程序的1/3到1/2,甚至更多。
- 注释分为序言性注释和功能性注释。
- 序言性注释:通常置于每个程序模块的开头部分,它应当给出程序的整体说明,对于理解程序本身具有引导作用。有些软件开发部门对序言性注释做了明确而严格的规定,要求程序编制者逐项列出。有关项目包括:
- 程序标题;
- 有关本模块功能和目的的说明;
- 主要算法;
- 接口说明:包括调用形式,参数描述,子程序清单;
- 有关数据描述:重要的变量及其用途,约束或限制条件,以及其它有关信息;
- 模块位置:在哪一个源文件中,或隶属于哪一个软件包;
- 开发简历:模块设计者,复审者,复审日期,修改日期及有关说明等。
- 功能性注释:功能性注释嵌在源程序体中,用以描述其后的语句或程序段是在做什么工作,或是执行了下面的语句会怎么样。而不要解释下面怎么做。
- 序言性注释:通常置于每个程序模块的开头部分,它应当给出程序的整体说明,对于理解程序本身具有引导作用。有些软件开发部门对序言性注释做了明确而严格的规定,要求程序编制者逐项列出。有关项目包括:
- 视觉组织:
- 空格、空行和缩进。
- 恰当地利用空格,可以突出运算的优先性。
- 自然的程序段之间可用空行隔开。
- 缩进也叫做向右缩格或移行。它是指程序中的各行不必都在左端对齐,都从第一格起排列。这样做使程序完全分不清层次关系。
- 对于选择语句和循环语句,把其中的程序段语句向右做阶梯式移行。使程序的逻辑结构更加清晰。
数据说明
在设计阶段已经确定了数据结构的组织及其复杂性。在编写程序时,则需要注意数据说明的风格。
为了使程序中数据说明更易于理解和维护,必须注意以下几点:
- 数据说明的次序应当规范化;
- 说明语句中变量安排有序化;
- 使用注释说明复杂数据结构。
- 数据说明的次序应当规范化:
- 数据说明次序规范化,使数据属性容易查找,也有利于测试,排错和维护。
原则上,数据说明的次序与语法无关,其次序是任意的。但出于阅读、理解和维护的需要,最好使其规范化,使说明的先后次序固定。
例如,在类型说明中可按如下顺序排列:
- 整型量说明
- 实型量说明
- 字符量说明
- 逻辑量说明
说明语句中变量安排有序化:
当多个变量名在一个说明语句中说明时,应当对这些变量按字母的顺序排列。 例如,把
integer size, length, width, cost, price 写成 integer cost, length, price , size, width
使用注释说明复杂数据结构:
如果设计了一个复杂的数据结构,应当使用注释来说明在程序实现时这个数据结构的特点。
例如, 对C的链表结构和Pascal中用户自定义的数据类型,都应当在注释中做必要的补充说明。
语句构造
在设计阶段确定了软件的逻辑结构,但构造单个语句则是编码阶段的任务。语句构造力求简单、直接,不能为了片面追求效率而使语句复杂化。
下面是关于语句构造的一些启发规则:
在一行内只写一条语句。
避免采用过于复杂的条件测试。
尽量减少 “非”条件的测试。
IF NOT ((CHAR<‘0’) OR (CHAR>‘9’)) THE… …
IF (CHAR>=‘0’) AND (CHAR<=‘9’) THE … …
避免大量使用循环嵌套和条件嵌套。
利用括号使逻辑表达式或算术表达式的运算次序清晰直观。
除非对效率有特殊的要求,程序编写要做到清晰第一,效率第二。不要为了追求效率而丧失了清晰性。事实上,程序效率的提高主要应通过选择高效的算法来实现。
程序要能直截了当地说明程序员的用意。
首先要保证程序正确, 然后才要求提高速度。反过来说,在使程序高速运行时,首先要保证它是正确的。
让编译程序做简单的优化。
尽可能使用库函数。
避免使用临时变量而使可读性下降。例如,有的程序员为了追求效率, 将
X=A [I] + 1/A [I] 写成 AI=A[I]; X=AI+1/AI,将一个计算公式拆成了几行。
避免不必要的转移。同时如果能保持程序可读性,则不必用 GOTO语句。
尽量只采用三种基本的控制结构来编写程序。
避免使用空的ELSE语句和IF… THEN IF…的语句。这种结构容 易使读者产生误解。例如:
IF (CHAR>=‘A’) THE
IF (CHAR<=‘Z’) THE
PRINT “This is a letter.”
ELSE
PRINT “This is not a letter.”
不要单独进行浮点数的比较,而是采用|x0-x1|<e
尽可能用通俗易懂的伪码来描述程序的流程,然后再翻译成必须使用的语言。
对于语句构造,可以列举出很多实践总结出来的经验规则。但是再多的规则都不如经常反躬自省:“如果我不是编码的人,那么能看懂它吗?”
输入/输出
关于输入和输出有下列的启发规则:
对所有的输入数据都要进行检验,识别错误的输入,以保证每个数据的有效性;
检查输入项的各种重要组合的合理性,必要时报告输入状态信息;
使得输入的步骤和操作尽可能简单,并保持简单的输入格式;
输入数据时,应允许使用自由格式输入;
应允许缺省值;
输入一批数据时,最好使用输入结束标志,而不要由用户指定输入数据数目;
在交互式输入输出时,要在屏幕上使用提示符 明确提示交互输入的请求,指明可使用选择项的种类和取值范围。同时,在数据输入的过程中和输入结束时,也要在屏幕上给出状态信息;
当程序设计语言对输入/输出格式有严格要求时,应保持输入格式与输入语句要求的一致性;
给所有的输出加注解,并设计输出报表格式。
输入/输出风格还受到许多其它因素的影响。如输入/输出设备(例如终端的类型,图形设备,数字化转换设备等)、用户的熟练程度、以及通信环境等。
效率问题
程序效率是指程序的运行速度及程序占用的存储空间。
效率是性能要求,因此应该在需求分析阶段确定效率方面的要求。
效率是靠好设计来提高的。
程序的效率和程序的简单程度是一致的,不要牺牲程序的清晰性和可读性来不必要地提高效率。
程序运行时间:源程序的效率直接由详细设计阶段确定的算法的效率决定,但是,写程序的风格也能对程序的执行速度和存储器要求产生影响。
写程序之前先简化算术的和逻辑的表达式;
仔细研究嵌套的循环,以确定是否有语句可以从内层往外移;
尽量避免使用多维数组;
尽量避免使用指针和复杂的表;
使用执行时间短的算术运算;
不要混合使用不同的数据类型;
尽量使用整数运算和布尔表达式。
存储器效率:
- 在大中型计算机中必须考虑操作系统页式调度的特点,一般说来,采用结构化程序设计,将程序功能合理分块,使每个模块或一组密切相关模块的程序体积大小与每页的容量相匹配,可减少页面调度和内外存交换,提高存储效率。
- 在微处理机中如果要求使用最少的存储单元,则应选用可生成较短目标代码且存储压缩性能优良的编译程序,在非常必要时可以使用汇编语言。
- 提高执行效率的技术通常也能提高存储器效率。提高存储器效率的关键同样是“简单”。
输入输出的效率:
- 简单清晰是提高人机通信效率的关键
- 硬件之间的通信效率是很复杂的问题,但是,从写程序的角度看,却有些简单的原则可以提高输入输出的效率
- 所有输入输出都应该有缓冲,以减少用于通信的额外开销;
- 对二级存储器(如磁盘)应选用最简单的访问方法;
- 二级存储器的输入输出应该以信息组为单位进行;
- 如果“超高效的”输入输出很难被人理解,则不应采用这种方法。
软件测试的目标
G. Myers给出了关于测试的一些规则,可以看作是测试的目标或定义:
测试是程序的执行过程,目的在于发现错误;
一个好的测试用例在于能发现至今未发现的错误;
一个成功的测试是发现了至今未发现的错误的测试。
软件测试的方法
测试方法分为黑盒测试和白盒测试两类。
如果已经知道了产品应该具有的功能,可以通过黑盒测试检验是否每个功能都能正常使用
如果已经知道了产品的内部工作过程,可以通过白盒测试来检验产品内部动作是否按照规格说明书的规定正常进行
黑盒测试
黑盒测试把测试对象看做一个黑盒子,测试人员完全不考虑程序内部的逻辑结构和内部特性,只依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明。黑盒测试又叫做功能测试(functional testing)或数据驱动测试。黑盒测试方法是在程序接口上进行测试,主要是为了发现以下错误:
- 是否有不正确或遗漏了的功能?
- 在接口上,输入能否正确地接受?能否输出正确的结果?
- 是否有数据结构错误或外部信息(例如数据文件)访问错误?
- 性能上是否能够满足要求?
- 是否有初始化或终止性错误?
黑盒测试不可能要求用所有可能的输入输出条件来确定测试数据。
白盒测试
白盒测试把测试对象看做一个透明盒子,它允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序的所有逻辑路径进行测试。通过在不同点检查程序的状态,确定实际的状态是否与预期的状态一致。白盒测试又称为结构测试(structural testing)、玻璃盒测试(glass-box testing)或逻辑驱动测试。
软件人员使用白盒测试方法,主要想对程序模块进行如下的检查:
- 对程序模块的所有独立的执行路径至少测试一次;
- 对所有的逻辑判定,取“真”与取“假”的两种情况都至少测试一次;
- 在循环的边界和运行界限内执行循环体;
- 测试内部数据结构的有效性等;
“错误潜伏在角落里,聚集在边界上”
软件测试步骤
- 模块测试(单元测试):把每个模块作为一个单独的实体来测试,发现的往往是编码和详细设计的错误。
- 子系统测试(集成测试):把经过单元测试的模块放在一起形成一个子系统来测试,着重测试模块的接口。
- 系统测试(集成测试):把经过测试的子系统装配成一个完整的系统来测试。发现的往往是软件设计中的错误,也可能发现需求说明中的错误。
- 验收测试(确认测试):把软件系统作为单一的实体进行测试,是在用户积极参与下进行的,而且可能主要使用实际数据(系统将来要处理的信息)进行测试。目的是验证系统确实能够满足用户的需要。发现的往往是系统需求说明书中的错误。
平行运行是同时运行新开发出来的系统和将被它取代的旧系统,以便比较新旧两个系统的处理结果。这样做的具体目的有如下几点:
- 可以在准生产环境中运行新系统而又不冒风险;
- 用户能有一段熟悉新系统的时间;
- 可以验证用户指南和使用手册之类的文档;
- 能够以准生产模式对新系统进行全负荷测试,可以用测试结果验证性能指标。
单元测试的测试重点
模块接口。主要检查下述几个方面:
- 参数的数目、次序、属性或单位系统与变元是否一致;
- 是否修改了只作输入用的变元;
- 全局变量的定义和用法在各个模块中是否一致。
局部数据结构:发现局部数据说明、初始化、默认值等方面的错误。
重要的执行通路:选择最有代表性、最可能发现错误的执行通路进行测试。
出错处理通路。当评价出错处理通路时,应该着重测试下述一些可能发生的错误:
- 对错误的描述是难以理解的;
- 记下的错误与实际遇到的错误不同;
- 在对错误进行处理之前,错误条件已经引起系统干预;
- 对错误的处理不正确;
- 描述错误的信息不足以帮助确定造成错误的位置。
边界条件。
- 软件常常在它的边界上失效 。
- 使用刚好小于、刚好等于和刚好大于最大值或最小值的数据结构、控制量和数据值的测试方案,非常可能发现软件中的错误。
单元测试的计算机测试
需要编写驱动程序(driver)和存根程序(stub)。
驱动程序也就是一个“主程序”,它接收测试数据,把这些数据传送给被测试的模块,并且印出有关的结果。
存根程序代替被测试的模块所调用的模块。因此存根程序也可以称为“虚拟子程序”。它使用被它代替的模块的接口,可能做最少量的数据操作,印出对入口的检验或操作结果,并且把控制归还给调用它的模块。
集成测试
集成测试是测试和组装软件的系统化技术。
由模块组装成程序时有两类方法:
- 非渐增式测试:先分别测试每个模块,再一下子把所有模块按设计要求放在一起结合成所要的程序。
- 渐增式测试:把下一个要测试的模块同已测试好的那些模块结合起来进行测试,依次类推,每次增加一个模块。这种方法实质上同时完成单元测试和集成测试。
根据集成测试的两类方法,大体上有四种集成策略:
一次性集成
自顶向下集成
自底向上集成
三明治集成
一次性集成
当所有组件都单独测试完毕之后,将它们一次性混合起来组成最终的系统,查看其是否能够运行成功。
缺点:
需要编写大量存根程序和驱动程序来测试独立的组件。
所有组件一次进行合并,很难找出所有错误的原因。
不容易区分接口错误与其他类型的错误。
自顶向下集成
从主控制模块开始,沿着程序的控制层次向下移动,逐渐把各个模块结合起来。在把附属于(及最终附属于)主控制模块的那些模块组装到程序结构中去时,或使用深度优先的策略,或使用宽度优先的策略。
优点:
- 自顶向下的结合策略能够在测试的早期对主要的控制或关键的抉择进行检验。
- 自顶向下测试不需要驱动程序。
- 如果选择深度优先的结合方法,可以在早期实现软件的一个完整的功能并且验证这个功能。
缺点:
- 需要编写存根程序。
- 为了充分地测试软件系统的较高层次,需要在较低层次上的处理。然而测试初期自下往上的重要数据流都缺失了。
- 存根程序需要的数量可能非常大。
自底向上集成
自底向上测试从“原子”模块(即在软件结构最低层的模块)开始组装和测试,不需要存根程序。当底层有许多组件是有多种用途的公用例程而经常被其他组件调用时、当设计是面向对象的或当系统由大量孤立的复用的组件组成时,自底向上方法是很有用的。
优点:
- 不需要编写存根程序。
- 测试驱动程序的数目较少。
缺点:
- 对顶层组件测试进行得晚,会推迟主要错误的发现。
- 顶层组件通常控制或影响计时,当系统的大部分处理都依赖于计时时(一般指和并发、实时性相关的操作和逻辑),很难自底向上进行测试。
三明治集成
将自顶向下策略与自底向上策略结合起来,在顶层使用自顶向下方法,而在较低的层使用自底向上方法。
这种策略的关键是选取结构图某一层为基准层(或称目标层),在其之下的层次采用自底向上方法,以为整个测试工作提供坚实的底层基础。选取不同的层次为基准层,则整个集成测试的活动情况相应会有很大不同。
优点:
- 允许在测试的早期进行集成测试。
- 结合了自顶向下和自底向上测试的优点,在测试的最开始就对控制和公用程序进行测试。
缺点:
- 在集成之前没有彻底地测试单独的组件。
回归测试
回归测试(regression test)是指重新执行已经做过的测试的某个子集,以保证由于调试或其他原
因引起的变化,不会导致非预期的软件行为或额外错误。
回归测试集(已执行过的测试用例的子集)包括下述3类不同的测试用例:
- 检测软件全部功能的代表性测试用例;
- 专门针对可能受修改影响的软件功能的附加测试;
- 针对被修改过的软件成分的测试。
确认测试
确认测试也叫验收测试,其目标是验证软件的有效性。
软件有效性的简单定义:如果软件的功能和性能如同用户所合理期待的那样,软件就是有效的。
因此,需求阶段产生的需求规格说明书或类似文档是软件有效性的标准,也是进行确认测试的基础。
确认测试以用户为主来进行。
Validation:确认指的为了保证软件确实满足了用户需求而进行的一系列活动
Verification:验证指的是保证软件正确地实现了某个特定要求的一系列活动
It is sometimes said that validation ensures that ‘you built the right thing’ and verification ensures that ‘you built it right’.
Alpha 和 Beta 测试
针对为许多客户开发的软件
Alpha测试由用户在开发者的场所进行,并且在开发者对用户的“指导”下进行测试。开发者负责记录发现的错误和使用中遇到的问题。总之,Alpha测试是在受控的环境中进行的。
Beta测试由软件的最终用户们在一个或多个客户场所进行。与Alpha测试不同,开发者通常不在Beta测试的现场,因此,Beta测试是软件在开发者不能控制的环境中的“真实”应用。
白盒测试的逻辑覆盖
逻辑覆盖是以程序内部的逻辑结构为基础的设计测试用例的技术。
- 语句覆盖
- 判定覆盖
- 条件覆盖
- 判定/条件覆盖
- 条件组合覆盖
- 点覆盖
- 边覆盖
- 路径覆盖
语句覆盖
语句覆盖就是设计若干个测试用例,运行被测程序,使得每一可执行语句至少执行一次。
测试用例的设计格式如下:
【输入的(A, B, X),输出的(A, B, X)】
判定覆盖
判定覆盖又叫分支覆盖,它的含义是,不仅每个语句必须至少执行一次,而且每个判定的每种可能的结果都应该至少执行一次,也就是每个判定的每个分支都至少执行一次。
换言之,就是设计若干个测试用例,运行被测程序,使得程序中每个判定的取真分支和取假分支至少经历一次。
条件覆盖
条件覆盖就是设计若干个测试用例,运行被测程序,使得程序中每个判定中的每个条件的可能取值至少执行一次。
条件覆盖通常比判定覆盖强 ,但也可能满足条件覆盖标准而并不满足判定覆盖标准
判定/条件覆盖
选取足够多的测试数据,使得判定表达式中的每个条件都取到各种可能的值,而且每个判定表达式也都取到各种可能的结果。
条件组合覆盖
条件组合覆盖就是设计足够的测试用例,运行被测程序,使得每个判定中条件的所有可能组合至少出现一次。
满足条件组合覆盖标准的测试数据,也一定满足判定覆盖、条件覆盖和判定/条件覆盖标准。因此,条件组合覆盖是前述几种覆盖标准中最强的。但是,满足条件组合覆盖标准的测试数据并不一定能使程序中的每条路径都执行到。
点覆盖
要求选取足够多的测试数据,使得程序执行路径至少经过流图的每个结点一次,由于流图的每个结点与一条或多条语句相对应,显然,点覆盖标准和语句覆盖标准是相同的。
边覆盖
要求选取足够多测试数据,使得程序执行路径至少经过流图中每条边一次。通常边覆盖和判定覆盖是一致的。
路径覆盖
路径覆盖就是设计足够的测试用例,程序的每条可能路径都至少执行一次(如果程序图中有环,则要求每个环至少经过一次) 。
控制结构测试
控制结构测试是根据程序的控制结构设计测试数据的技术
基本路径测试
条件测试
循环测试
基本路径测试
使用这种技术设计测试用例时,首先计算程序的环形复杂度,并用该复杂度为指南定义执行路径的基本集合,从该基本集合导出的测试用例可以保证程序中的每条语句至少执行一次,而且每个条件在执行时都将分别取真、假两种值。
根据过程设计结果画出相应的流图。
计算流图的环形复杂度。
确定线性独立路径的基本集合。
- 独立路径是指至少引入程序的一个新处理语句集合或一个新条件的路径,用流图术语描述,独立路径至少包含一条在定义该路径之前不曾用过的边。
- 程序的环形复杂度决定了程序中独立路径的数量,而且这个数是确保程序中所有语句至少被执行一次所需的测试数量的上界
设计可强制执行基本集合中每条路径的测试用例。
- 每个测试用例执行之后,与预期结果进行比较。如果所有测试用例都执行完毕,则可以确信程序中所有的可执行语句至少被执行了一次,而且每个条件都分别取过true值和false值。
- 应该注意,某些独立路径不能以独立的方式测试,也就是说,程序的正常流程不能形成独立执行该路径所需要的数据组合(例如,为了执行本例中的路径1,需要满足条件total.valid>0)。在这种情况下,这些路径必须作为另一个路径的一部分来测试。
循环测试
循环测试是一种白盒测试技术,它专注于测试循环结构的有效性。
在结构化的程序中通常只有3种循环,即简单循环、串接循环和嵌套循环。
- 简单循环:应该使用下列测试集来测试简单循环,其中n是允许通过循环的最大次数。
跳过循环。
只通过循环一次。
通过循环两次。
通过循环m次,其中m<n-1。
通过循环n-1,,n+1次。
- 嵌套循环
直接把简单循环测试方法应用于嵌套循环,会使测试数目以几何级数增长。为减少测试数,B.Beizer提出嵌套循环的测试策略:
从最内层循环开始测试,把所有其他循环都设置为最小值。
对最内层循环使用简单循环测试方法,而使外层循环的迭代参数(例如,循环计数器)取最小值,并为越界值或非法值增加一些额外的测试。
由内向外,对下一个循环进行测试,但保持所有其他外层循环为最小值,其他嵌套循环为“典型”值。
继续进行下去,直到测试完所有循环。
(3)串接循环
如果串接循环的各个循环都彼此独立,则可以使用前述的测试简单循环的方法来测试串接循环。但是,如果两个循环串接,而且第一个循环的循环计数器值是第二个循环的初始值,则这两个循环并不是独立的。当循环不独立时,建议使用测试嵌套循环的方法来测试串接循环。
黑盒测试
黑盒测试的方法主要有:
- 等价划分
- 边界值分析
- 错误推测
等价划分
等价划分方法把所有可能的输入数据,即程序的输入域划分成若干部分,据此导出测试用例,一个理想的测试用例能够独自发现一类错误。
等价划分法的一个假设:每类中的一个典型值在测试中的作用与这一类中所有其他值的作用相同。
在确定输入数据的等价类时,常常还需要确定输出数据的等价类,以便根据输出数据的等价类导出对应的输入数据的等价类。
等价类的划分有两种不同的情况:
- 有效等价类:是指对于程序的规格说明来说,是合理的,有意义的输入数据构成的集合。
- 无效等价类:是指对于程序的规格说明来说,是不合理的,无意义的输入数据构成的集合。
如果输入条件规定了取值范围或值的个数,则可以确立一个有效等价类和两个无效等价类。
如果输入条件规定了输入值的集合,或者是规定了“必须如何”的条件,这时可确立一个有效等价类和一个无效等价类。
如果规定了输入数据的一组值,而且程序要对每个输入值分别进行处理。这时可为每一个输入值确立一个有效等价类,此外针对这组值确立一个无效等价类,它是所有不允许的输入值的集合。
如果规定了输入数据必须遵守的规则,则可以确立一个有效等价类(符合规则)和若干个无效等价类(从不同角度违反规则)。
如果规定了输入数据为整型,则可以划分出正整数、零和负整数等3个有效类。
如果程序的处理对象是表格,则应该使用空表,以及含一项或多项的表。
设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖的有效等价类,重复这一步,直到所有的有效等价类都被覆盖为止;
设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类,重复这一步,直到所有的无效等价类都被覆盖为止。
软件可靠性
软件可靠性:是程序在给定的时间间隔内,按照规格说明书的规定成功地运行的概率。
软件可用性:是程序在给定的时间点,按照规格说明书的规定成功地运行的概率。
R(250)=0.95表示100个相同的系统有95个无故障运行250小时,有5个在此期间发生故障
A(250)=0.95表示100个相同的系统都运行了250个小时,有95个处于正常运行状态,5个出现故障等待处理.
为简化所讨论的问题,我们假定软件的故障率是不随时间变化的常量,则根据经典的软件可靠性理论,
当耗损或退化存在时,故障率随时间的流失而线性增加(这种模型一般不适用于软件产品)
如果在一段时间内,软件系统故障停机时间分别为td1, td2,…,正常运行时间分别为tu1, tu2….,则系统的稳态可用性为:
其中,
如果引入系统平均无故障时间MTTF和平均维修时间MTTR的概念,则(7.1)式可以变成:
平均维修时间MTTR是修复一个故障平均需要用的时间,它取决于维护人员的技术水平和对系统的熟悉程度,也和系统的可维护性有重要关系,
平均无故障时间MTTF是系统按规格说明书规定成功地运行的平均时间,它主要取决于系统中潜伏的错误的数目,因此和测试的关系十分密切。
估算平均无故障时间点方法
符号
在估算MTTF的过程中使用下述符号表示有关的数量:
- :测试之前程序中错误总数;
- :程序长度(机器指令总数);
- :测试(包括调试)时间;
- :在至期间发现的错误数;
- :在至期间改正的错误数。
基本假定
在类似的程序中,单位长度里的错误数 近似为常数,满足 。
失效率正比于软件中剩余的(潜藏的)错误数,而平均无故障时间 MTTF 与剩余的错误数成反比。
为了简化讨论,假设发现的每一个错误都立即正确地改正了(即调试过程没有引入新的错误)。因此:
估算平均无故障时间
经验表明,平均无故障时间与单位长度程序中剩余的错误数成反比,即:
其中 为常数,其值应根据经验选取。美国的一些统计数字表明, 的典型值是 200。
估计错误总数的方法
(1) 植入错误法
使用这种估计方法,在测试之前由专人在程序中随机地植入一些错误,测试之后,根据测试小组发现的错误中原有的和植入的两种错误的比例,来估计程序中原有错误的总数 。
假设人为地植入的错误数为 ,经过一段时间的测试之后发现了 个植入的错误,此外还发现了 个原有的错误。如果可以认为测试方案发现植入错误和发现原有错误的能力相同,则能够估计出程序中原有错误的总数为:
(2) 分别测试法
随机地把程序中一部分原有的错误加上标记,然后根据测试过程中发现的有标记错误和无标记错误的比例,估计程序中的错误总数。
为了随机地给一部分错误加标记,分别测试法使用两个测试员(或测试小组),彼此独立地测试同一个程序的两个副本,把其中一个测试员发现的错误作为有标记的错误。
具体做法是,在测试过程的早期阶段,由测试员甲和测试员乙分别测试同一个程序的两个副本,由另一名分析员分析他们的测试结果。用 表示测试时间,假设:
- 时错误总数为 ;
- 时测试员甲发现的错误数为 ;
- 时测试员乙发现的错误数为 ;
- 时两个测试员发现的相同错误数为 。
假定测试员乙发现有标记错误和发现无标记错误的概率相同,则可以估计出测试前程序中的错误总数为:
在测试一个长度为48000条指令的程序时,第一个月由甲、乙两名测试员各自独立测试这个程序。经过一个月测试后,甲发现并改正20个错误,使MTTF达到8h。与此同时,乙发现24个错误,其中的6个甲也发现了。以后由甲一人继续测试这个程序。问:
(1)刚开始测试时程序中总共有多少个潜藏的错误?
(2)为使MTTF达到240h,必须再改正多少个错误?
(1) ET=24/6×20=80
(2) 因为8=48000/(K(ET-20))=48000/(K×60)
所以K=100;
因为240=48000/(100(80-EC))
所以EC=78
为了使平均无故障时间达到240h,总共要改正78个错误,测试员甲在与乙分别测试时已经改正了20个错误,因此,还需要改正58个错误。
软件维护
软件维护的定义
软件维护:就是在软件已经交付使用之后,为了改正错误或满足新的需要而修改软件的过程。
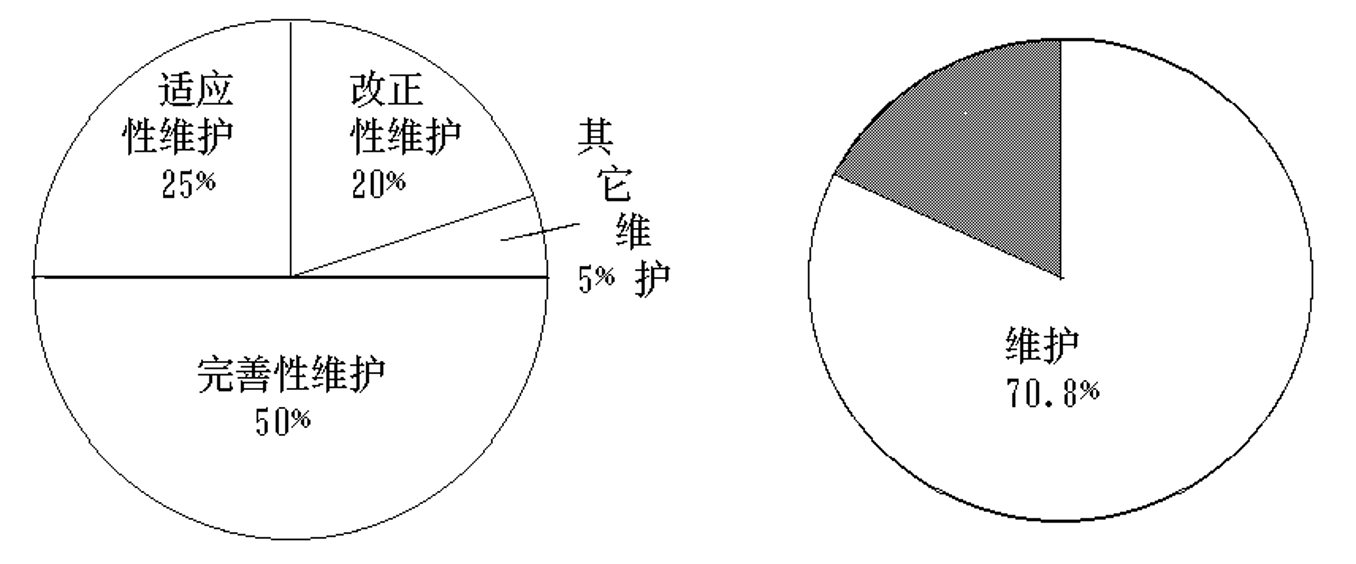
维护的类型:
- 改正性维护(Corrective maintenance)
- 适应性维护(Adaptive maintenance)
- 完善性维护(Perfective maintenance)
- 预防性维护(Preventive maintenance)
维护报告
维护要求表或称软件问题报告表,由申请维护的用户填写。
软件修改报告,由软件组织内部制定,要指明:
- 满足某个维护要求表中提出的要求所需要的工作量;
- 维护要求的性质;
- 这项要求的优先级;
- 与修改有关的事后数据;
软件的可维护性
软件的可维护性:维护人员理解、改正、改动或改进这个软件的难易程度。
决定软件可维护性的因素:
- 文档
- 可维护性复审
决定软件可维护性的因素
- 可理解性:软件可理解性表现为外来读者理解软件的结构、功能、接口和内部处理过程的难易程度。
- 可测试性:诊断和测试的容易程度取决于软件容易理解的程度。良好的文档对诊断和测试是至关重要的,此外,软件结构、可用的测试工具和调试工具,以及以前设计的测试过程也都是非常重要的。
- 可修改性:软件容易修改的程度和设计原理和启发规则直接有关。
- 可移植性:软件可移植性指的是,把程序从一种计算环境(硬件配置和操作系统)转移到另一种计算环境的难易程度。
- 可重用性:所谓重用(reuse)是指同一事物不做修改或稍加改动就在不同环境中多次重复使用。
用户文档
用户文档至少应该包括下述5方面的内容:
- 功能描述,说明系统能做什么;
- 安装文档,说明怎样安装这个系统以及怎样使系统适应特定的硬件配置;
- 使用手册,简要说明如何着手使用这个系统(应该通过丰富例子说明怎样使用常用的系统功能,还应该说明用户操作错误时怎样恢复和重新启动);
- 参考手册,详尽描述用户可以使用的所有系统设施以及它们的使用方法,还应该解释系统可能产生的各种出错信息的含义(对参考手册最主要的要求是完整,因此通常使用形式化的描述技术);
- 操作员指南(如果需要有系统操作员的话),说明操作员应该如何处理使用中出现的各种情况。
系统文档
所谓系统文档指从问题定义、需求说明到验收测试计划这样一系列和系统实现有关的文档。
- 描述系统设计、实现和测试的文档对于理解程序和维护程序极端重要
- 从概貌到每个方面每个特点,从抽象到具体,有逻辑地介绍系统
可维护性复审
- 在需求分析阶段的复审过程中,应该对将来要改进的部分和可能会修改的部分加以注意并指明;应该讨论软件的可移植性问题,并且考虑可能影响软件维护的系统界面。
- 在正式的和非正式的设计复审期间,应该从容易修改、模块化和功能独立的目标出发,评价软件的结构和过程;设计中应该对将来可能修改的部分预作准备。
- 代码复审应该强调编码风格和内部说明文档这两个影响可维护性的因素。
- 设计和编码过程中尽量使用可重用的软件构件。
- 在测试结束时进行最正式的可维护性复审,这个复审称为配置复审。配置复审的目的是保证软件配置的所有成分是完整的、一致的和可理解的,而且为了便于修改和管理已经编目归档了。
- 在完成了每项维护工作之后,都应该对软件维护本身进行仔细认真的复审。
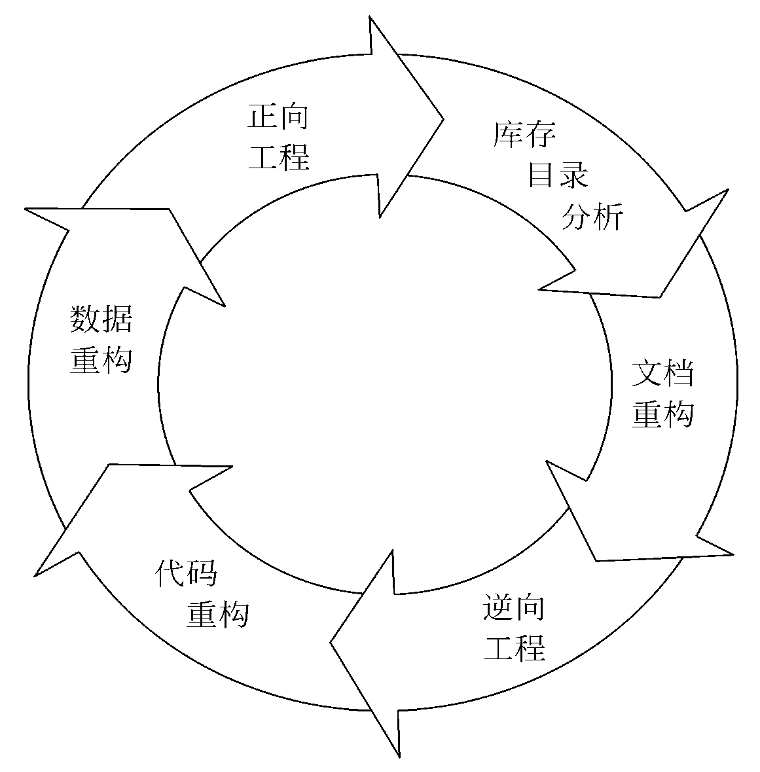
软件工程再工程过程
以软件工程方法学为指导,对程序全部重新设计、重新编码和测试,为此可以使用CASE工具(逆向工程和再工程工具)来帮助理解原有的设计。
库存目录分析->文档重构->逆向工程->代码重构->数据重构->正向工程
面向对象方法学引论
什么是面向对象
Coad和Yourdo给出了一个定义:“面向对象=对象+类+继承+通过消息进行通信”一个面向对象的程序的每一成份应是对象,计算是通过新的对象的建立和对象之间的通信来执行的。这个定义的要点 :
- 认为客观世界是由各种对象组成的,任何事物都是对象,复杂的对象可以由比较简单的对象以某种方式组合而成;
- 把所有对象都划分成各种对象类(简称为类,class),每个对象类都定义了一组数据和一组方法。;
- 按照子类(或称为派生类)与父类(或称为基类)的关系,把若干个对象类组成一个层次结构的系统(也称为类等级);
- 对象彼此之间仅能通过传递消息互相联系。
面向对象建模
模型:为了理解事物而对事物作出的一种抽象,是对事物的一种无歧义的书面描述
模型由一组图示符号和组织这些符号的规则组成,利用它们来定义和描述问题域中的术语和概念
模型是一种思考工具,把知识规范地表示出来
为什么是Model?建模实现了四个目标:
- 帮助将系统可视化为想要的样子。
- 允许指定系统的结构或行为。
- 给你一个模板,指导你构建一个系统。
- 记录所做的决定。
构建复杂系统的模型是因为无法完整地理解这样的系统。您构建模型以更好地理解您正在开发的系统。
软件团队通常不建模许多软件团队构建处理问题的应用程序,就像构建纸飞机一样
- 从项目需求开始编码
- 工作更长的时间并创建更多代码
- 缺乏任何计划的架构
- 注定会失败
建模是成功项目的常见线索
建模的四个原则
您创建的模型会影响攻击问题的方式。 每个模型都可以以不同的精确度来表达。 最好的模型与现实息息相关。 没有单一的模型是足够的。
UML
UML有4种关系:
- 关联关系:有联系
- 依赖关系:使用
- 泛化关系:特殊到一般
- 实现关系:规约到解决方案
- 没有组合、聚合、包含!
UML有9种图:
- Use Case图/用例图:展示Use Case、Actor及其关系;
- 类图:展示类、接口、包及其关系;
- 顺序图/时序图:按时序展示对象间消息传递;
- 协作图:强调收发消息的对象间的组织结构;
- 状态图:展示对象在其生命周期中的可能状态以及在这些状态上对事件的响应;
- 活动图:展示系统从一个活动转到另一活动的可能路径和判断条件;
- 对象图:某个时间点上系统中各对象的快照;
- 构件图:展示系统各构件及其关系;
- 配置图/部署图:展示交付系统中软硬件间物理关系;
Use Case/用例图
Use Case 图主要用于描述系统和外部环境的关系。
Use Case:对系统提供的功能的一种描述。(A use case describes behavior that the system exhibits to benefit one or more actors.)
Actor:可能使用这些Use Case的人或外部系统。(Actors are roles adopted by things that interact directly with system. A role is like a hat that something wears in a particular context.)
系统边界:Use Case在内,Actor在外;
用例之间的关系:《extend》、《include》、Generalizatio

Actor与Use Case间的连线称为通信关联,表示Actor与相应Use Case的交互。
无论有无箭头,通信关联都表示双向会话,箭头表示Actor触发Use Case。
顺序图
顺序图描述几个对象间的动态协作关系,一个对象通过发送消息与其他对象相互作用。一个对象对消息的接收触发一个操作的执行,从而可能给其他对象发消息。
顺序图对识别 Use Case 中的附加对象很有用:
- 包含在 Use Case中的对象称为参与对象;
- 顺序图展示了这些对象间传送消息的时间顺序,反映了对象之间的一次特定交互过程;
UML 的三种扩展机制
- 标记值(Tagged Value)
- 附属于UML元素的各种信息(Property)
- 具有形式:{属性名 = 值}
- 约束(Constraint)
- UML中限制一种或多个元素语义的规则
- 形式:{约束条件}
- 构造型(Stereotype)
- 构造型机制是指在已有的模型元素基础上建立一种新的模型元素。它与现有元素要相差不多,只是多一些特别的语义
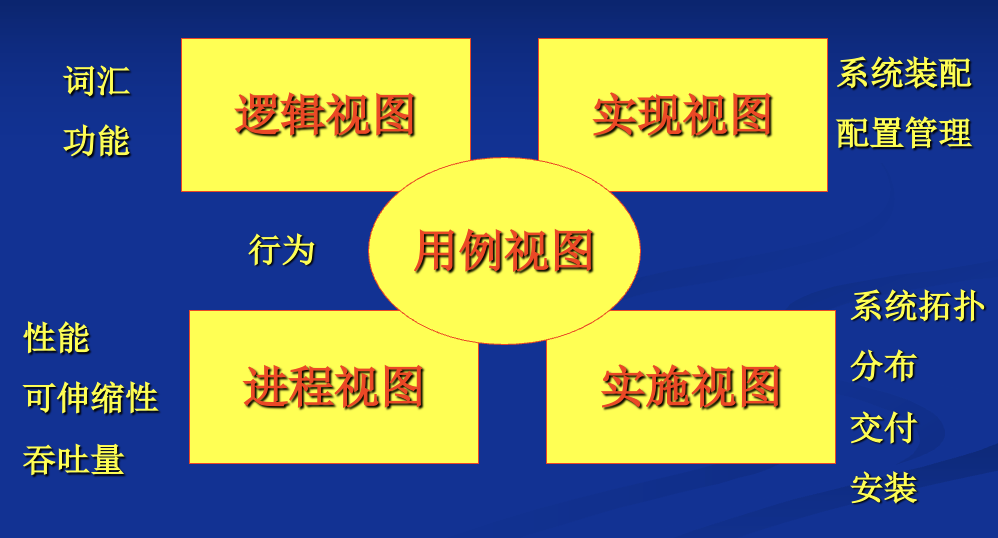
用 UML 描述系统的 5 个视图
面向对象分析
Use Case
Use Case的引出(Why Use Case?)
了解需求->分析典型用例->不自觉、随意、潦草->Jacobso提出Use Case分析法-> OO技术进入第二代;
Use Case是什么:
- 本质上,一个 Use Case 是用户与计算机之间为达到某个目的的一次典型交互作用;
- 作为结果,Use Case代表的是系统的一个完整功能。
Use Case的表达形式:
- 自然语言、活动图等;
UML 的 Use Case图描述的是Use Case模型;
用户目标和系统交互功能
- 系统交互功能:用户在系统中为达某种目的所要做的事情;
- 用户目标:用户所要达到的真正目标。
二者一个是目的,一个是手段,应首先定义Use Case来满足目的,再来定义针对目标的“手段”Use Case。
Actor:
- Actor是与系统交互的外部实体;
- Actor是具有构造型<<Actor>>的类,所以谈论Actor时考虑的是其角色,而非角色的实例;
- Use Case总是由Actor启动的;
- Actor与Use Case间是多对多的关系。
- Actor有助于获取Use Case
- 先找出各Actor,再通过他们得到Use Case。
处理Actor与Use Case的关系
- 一般不必过分关注Actor的细节;
- 若需对系统分析优化,应了解Actor细节;
- 对每个用户,提供一张Actor列表,指明其可以扮演的角色,即可以执行的Use Case,有助于协调需求冲突、制定安全策略。
Use Case的描述:
- Use Case的名字:唯一标识
- 参与的Actor(s):标出其中的主动Actor
- 入口条件:Use Case启动前需要的条件
- 事件流:Use Case的动作序列
- 出口条件:完成后应满足的条件
- 特殊需求:非功能性需求
场景(Scenario):
- 场景是Use Case的真实例子;
- 场景通过举例说明情况,帮助理解问题域,进而归纳Use Case;
- 具体执行一次Use Case,得到一个场景;
- 场景重在可理解性,Use Case重在完整性。
注意:场景是Use Case的实例,因此其名字带有下划线(对象)
Use Case 之间的关系
Use Case间的关系:包含、扩展、泛化
- 包含:两个Use Case,如果其中一个在其事件流中包含了另一个,那么它们间就有包含关系。
- 扩展:将常规动作放在一个基本Use Case中,将非常规动作放在其扩展Use Case中。
- 泛化:对一般性Use Case做特殊化、细化。
面向对象分析
需求提取->Use Case和场景形式的需求说明->细化描述、规范和形式化->形成分析模型
分析模型要:准确、完整、一致、可检验。它其实对应着传统的需求规约文档,但同时它也包含系统高层设计的起始部分。
分析模型包括:
- 功能模型:Use Case图表示
- 对象模型:类图、对象图表示
- 动态模型:顺序图、状态图表示
分析的活动:
- 提取“分析类”(也叫“分析对象”);
- 转述Use Case或场景;
- 整理“分析类”;
分析类的含义
- “分析类”是概念层的内容,从它们可捕获系统对象模型的雏形;
- “分析类”相当粗略,并且,不要往其中添加技术细节。
分析类的划分
划分原则:要尽量减小需求变化的影响——“高内聚、低耦合”。
实体类:系统要记录和维护的信息;
边界类:系统和外部要素间交互的边界;
控制类:Use Case中行为的协调;
可以用构造型表示:<
也可以用特殊图示表示:

实体类描述必须存储的信息,以及与这些信息直接相关的操作;
实体类与系统外部环境以及特定Use Case的控制逻辑要弱耦合。
边界类描述系统外部环境与内部运作之间的交互;
主要负责内容的翻译、形式的转换,并表达相应结果;
边界类把系统其他部分(实体类、控制类)与外部环境隔离;
注意这是概念层,不是要做具体界面。
控制类描述一个Use Case特有的事件流中的控制行为,起协调人作用;
控制类把Use Case特有的行为与系统其他部分(实体类、边界类)隔离开来;
从而,实体类和边界类有可能跨越多个Use Case。
实体类:从参与对象中选取。
边界类:通常,一个Actor与Use Case之间的通信关联对应一个边界类。
控制类:通常,一个Use Case对应一个控制类。
标识实体对象的试探法
为理解Use Case,开发人员或用户需要阐明的术语
Use Case中反复出现的名词(如,事件)
系统需要一直跟踪的现实世界的实体(如,现场工作人员、资源)
系统需要一直跟踪的现实世界的活动(如,紧急操作计划)
Use Case本身(如,报告紧急情况)
数据源点或终点(如,打印机)
总是使用的用户术语
确定用户需要将数据输入系统的窗口或表格(如,紧急情况报告表单,报告紧急情况按钮)
确定系统对用户的响应或消息(如,确认通知)
不要用边界对象对界面的可视方面建模(用户模型更适于做这件事)
总是使用用户的术语而不是实现技术的术语来描述界面
为每个Use Case标识一个控制对象,如果Use Case比较复杂并且能分解成更短的事件流,则为该Use Case标识多个控制对象
为Use Case中的每个Actor标识一个控制对象
一个控制对象的生命周期应该是对应Use Case的范围或一个用户界面的范围。如果很难确定一个控制对象活动的开始和结束,则表明对应的Use Case可能没有一个明确定义的入口和退出条件
转述 Use Case 或场景
把文字描述的Use Case表述为UML的交互图。
顺序图:联系Use Case与分析对象。表示Use Case的行为如何在各分析对象间分布。
协作图:“分析对象”间的“连接”关系。
面向对象设计

软件项目管理
Gantt 图的三个缺点
- 不能显式地描绘各项作业彼此间的依赖关系;
- 进度计划的关键部分不明确,难于判定哪些部分应当是主攻和主控的对象;
- 计划中有潜力的部分及潜力的大小不明确,往往造成潜力的浪费。
工程网络
工程网络是制定进度计划时另一种常用的图形工具;
它能描绘任务分解情况以及每项活动/作业的开始时间和结束时间,此外,它还显式地描绘各个作业彼此间的依赖关系;
工程网络图要求绘制者理解项目中哪些部分可以并行;
活动的并行执行还取决于其执行者是否是一个人/单位;
注意区分活动与里程碑:
活动(Activity):一个活动是项目的一部分,它要耗费一段时间,有开始和结束。
里程碑(Milestone):一个里程碑是某个活动完成的标志,它是一个特定的时间点。
用箭头表示活动/作业;
用圆圈表示里程碑/事件。
活动的四个参数:
前置条件(Precursor):活动开始前必须发生的事件。
持续时间(Duration):完成活动所需的时间。
最终期限(Due Date):日期,活动必须在此之前完成。
结束点(Endpoint):通常是活动对应的里程碑或可交付成果。
软件项目中的人员组织
为了成功地完成软件开发工作,项目组成员必须以一种有意义且有效的方式彼此交互和通信。如何组织项目组是一个重要的管理问题,管理者应该合理地组织项目组,使项目组有较高生产率,能够按预定的进度计划完成所承担的工作。经验表明,项目组组织得越好,其生产率越高,而且产品质量也越好。
民主制程序员组
民主制程序员组的一个重要特点是,小组成员完全平等,享有充分民主,通过协商做出技术决策。因此,小组成员之间的通信是平行的.如果小组内有个成员,则可能的通信信道共有n(n-1)/2条。
一般说来,程序设计小组的规模应该比较小,以2—8名成员为宜 。
民主制程序员组通常采用非正式的组织方式 。
主要优点 :
- 组员们对发现程序错误持积极的态度 。
- 组员们享有充分民主.小组有高度凝聚力,组内学术空气浓厚,有利于攻克技术难关。
主程序员组
采用这种组织方式主要出于下述几点考虑:
- 软件开发人员多数比较缺乏经验;
- 程序设计过程中有许多事务性的工作,例如,大量信息的存储和更新;
- 多渠道通信很费时间,将降低程序员的生产率。
主程序员组用经验多、技术好、能力强的程序员作为主程序员,同时,利用人和计算机在事务性工作方面给主程序员提供充分支持,而且所有通信都通过一两个人进行。
主程序员组的两个重要特性: 专业化和层次性。
- 主程序员:既是成功的管理员,又是高度熟练的程序员,要负责体系结构和其他关键复杂部分的设计,协调其他成员,复查其他成员的工作,对每行代码负责。
- 后备程序员:主程序员的“替补”。要和主程序员一样能干。
- 编程秘书:负责完成与项目有关的全部事务性工作,例如,维护项目资料库、文档,甚至源码的编译、链接、运行等。
主程序员小组存在的问题:
- 主程序员很难找到:成功的管理员、高度熟练的程序员的结合体;
- 后备程序员更难找到:高能力、高素质却要甘居“全场替补板凳队员”;
- 编程秘书也不容易找到
软件规模估算
- 代码行技术:这种方法依据以往开发类似产品的经验和历史数据,估计实现一个功能所需要的源程序行数。
- 功能点技术:看交付的软件的总功能有多少。依赖对软件信息域特性和软件复杂性的评估结果估算软件规模。功能点(FP)和对象点是这种估算中常用的指标。
衡量软件规模的代码行指标
项目 工作量(人月) 元(千) 规模 (KLOC) 文档页数 错误数 开发人数 aaa-01 24 168 12.1 365 29 3 ccc-04 62 440 27.2 1224 86 5 fff-03 43 314 17.5 1050 64 6
- 生产率 = KLOC/PM(人月)
- 成本 = 元/LOC
- 质量 = 错误数/KLOC
- 文档 = 文档页数/KLOC
代码行方法存在的问题:
- 严重依赖项目所使用的开发语言。对使用不同语言开发相同项目的情况,单独比较代码行数值没有意义。
- 不同开发组织可以制定不同的代码行计数标准,所以依据代码行指标在组织间类比生产率一般是不可能的。
- 代码行方法主要度量编码阶段的工作量,源程序仅是软件配置的一个成分,用它的规模代表整个软件的规模似乎不太合理。
- 若采用的编码方法和语言在表达和解决问题方面效率高,用这种方法计算的生产率反而会低。
用功能点衡量的软件规模
功能点用系统的功能数量来衡量其规模。
对系统中以下几类部分计数(信息域特性):
输入项数:用户向软件输入的项数。这些输入给软件提供面向应用的数据。输入不同于查询,后者单独计数,不计入输入项数中。
输出项数:软件向用户输出的项数。它们向用户提供面向应用的信息,例如,报表和出错信息等。报表内的数据项不单独计数。
查询数:查询即是一次联机输入,它导致软件以联机输出方式产生某种即时响应,即一对“请求-响应” 。
主文件数:逻辑主文件(即数据的一个逻辑组合,它可能是大型数据库的一部分或是一个独立的文件)的数目。
外部接口数:机器可读的全部接口(例如,磁盘或磁带上的数据文件)的数量,用这些接口把信息传送给另一个系统。
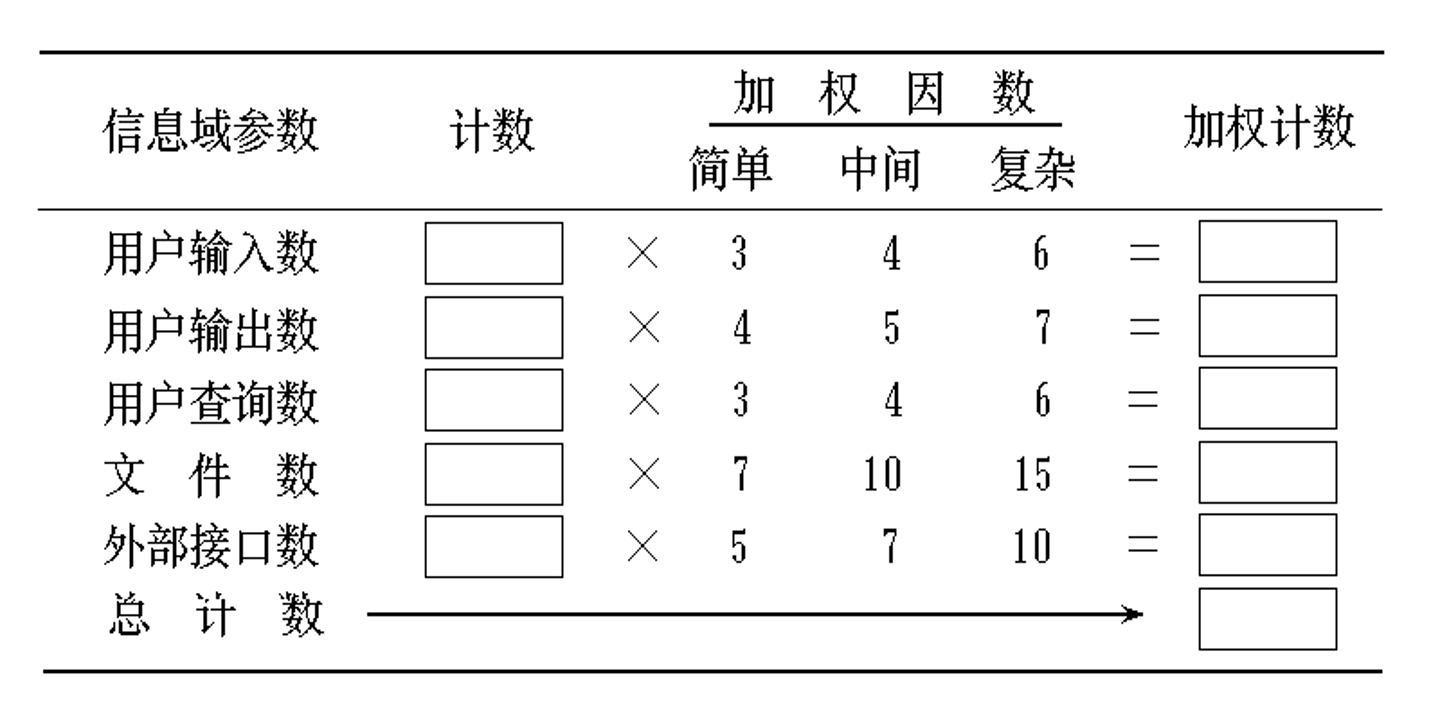
由各项的计数同与其对应的复杂度权重计算加权和,此为未经调整的功能点计数(UFP)。
技术复杂度因子(TCF)的组成
F1-可靠的备份和恢复
F2-数据通信
F3-分布式处理功能
F4-性能
F5-大量使用的配置
F6-联机数据输入
F7-操作简便性
F8-在线升级
F9-复杂界面
F10-复杂数据处理
F11-重复使用性
F12-安装简便性
F13-多工作点安装
F14-易于修改
功能点的计算
前面根据计数和复杂度权重得出的加权和是未经调整的功能点计数(UFP);
TCF的每一部分取值为0到5,0表示该部分对系统没有影响,5表示该部分对系统很重要;
TCF = 0.65 + 0.01(SUM(Fi));
TCF的取值在0.65到1.35之间;
最后,功能点计算公式为:FP = UFP × TCF
生产率 = FP/PM(人月)
成本 = 元/FP
质量 = 错误数/FP
文档 = 文档页数/FP
根据专家经验来估算软件工作量
使用代码行或功能点方法,估算出乐观值a、悲观值b、最可能值m;
计算期望值S = (a + 4m + b) / 6;
使用生产率的历史数据(KLOC/PM、FP/PM),得出估算的工作量;
这种方法使用的历史数据应注意更新调整,以适应当前时期与当前的工作环境。
Delphi 技术-专家判定的改进
邀请位专家,在小组会议上讨论项目估算;
每位专家得出一个期望值Si,并无记名提交;
会议组织者计算S=SUM(Si) / n;
每位专家根据S,可以考虑修改自己的Si,并再次无记名提交;
重复以上两步骤,直到各位专家不愿再修改自己的Si。
专家经验法的不足:
依赖主观判断:受专家经验、能力、偏好等不准确性影响;
按比例是不可靠的:项目成本不总是线性的。“两个人的效率不是一个人的两倍”;
过于简化:忽略了能影响工作量的大量因素,如产品性能、人员素质、项目特殊要求等方面。
风险管理的内容
估算模型是利用从过去的软件项目收集得到的数据进行统计分析而导出的。
软件规模通常是估算模型的主要因素,由它得出初步估计后,再根据许多次要调节因素进行调整。
估算模型种类:
静态单变量模型
动态多变量模型(考虑了时间的因素)
风险识别和风险的类型
- 项目风险:威胁项目计划
- 技术风险:威胁所开发软件的质量及交付时间
- 商业风险:威胁所开发软件的生存能力
- 市场风险:没有人需要的产品
- 策略风险:公司不打算支持的产品
- 销售风险:销售性差的产品
- 管理风险:建造中缺乏“关爱”的产品
- 预算风险:没有投入足够的资金和人工的产品
软件项目的核心风险
- 进度安排的先天错误
- 安排时间和工作量时犯下的错误。对规模的判断失误、预算的彻底失败。
- 需求膨胀
- 在开发的过程当中,客户的业务领域不可能始终静止不变;
- 从项目的角度来看,需求总是向着膨胀的方向变化;
- 合理的开发逻辑应该考虑到需求变化的可能程度而在制定的计划中允许一定限度的改变。
- 人员的流失
- 需要掌握技术人员的年平均流动率,以及新人工作能“上手”的最短时间,从而为项目分配一定的缓冲人力资源。
- 规约崩溃
- 问题的本质是在项目启动阶段商谈需求范围时没有谈拢;
- 实际中有可能掩盖严重的冲突而定下一个让每一方勉强接受的含混不清的目标而开始项目;
- 直到项目明确满足规约要求时此风险才消失。
软件配置管理(SCM)
何为软件配置管理:
- 配置管理的目的是针对变化、控制变化;
软件配置管理的目标是:
- 标识变更
- 控制变更
- 确保变更正确地实现
- 向其他有关的人报告变更
简言之:软件配置管理是软件系统发展过程中管理和控制变化的规范。
软件配置管理(Software Configuration Management)是一门应用技术、管理和监督相结合的学科,通过标识和文档来记录配置项的功能和物理特性、控制这些特性的变更、记录和报告变更的过程和状态,并验证它们与需求是否一致。
注意:软件配置管理不同于软件维护。
软件配置
软件配置项(Software Configuration Item) :为了配置管理而作为单独实体处理的一个工作产品或一段软件,简称SCI。简单说,就是软件过程输出的全部计算机程序、文档、数据。
配置管理聚集:SCI的一个组合。简称CM聚集。
版本:在一确定的时间点上,某个SCI或某个配置的状态。
为了开发出高质量的软件产品,软件开发人员不仅要努力保证每个软件配置项正确,而且必须保证一个软件的所有配置项是完全一致的。
基线(baseline):IEEE把基线定义为:已经通过了正式复审的规格说明或中间产品,它可以作为进一步开发的基础,并且只有通过正式的变化控制过程才能改变它。
基线就是通过了正式复审的软件配置项。
项目数据库:
一旦一个SCI成为基线,就被存放到项目数据库中;
项目数据库和变更控制规程相结合,保护着项目的基线;
软件配置管理过程
软件配置管理主要有5项任务:
- 标识
- 版本控制
- 变化控制
- 配置审计
- 配置状态报告
标识软件配置中的对象:
- 必须单独命名每个配置项,然后用面向对象方法组织它们 。
- 每个对象都有一组能唯一地标识它的特征:名字、描述、资源表和“实现”。
- 所设计的标识模式必须能无歧义地标识每个对象的不同版本。
能力成熟度模型(CMM)
持续的过程改进基于许多细小的、逐渐发展的步骤,而不是革命性的革新。CMM提出的框架中,将这些步骤组织为五个成熟度等级,为持续的过程改进提供了基础:
等级1:初始级(Initial)
等级2:可重复级(Repeatable)
等级3:已定义级(Defined)
等级4:已管理级(Managed)
等级5:优化级(Optimizing)
一个成熟度等级是经过严格定义的、且达到成熟软件过程的发展阶梯
每个成熟度等级由一组过程目标集合(关键过程域)组成,一旦满足这些目标,就能确定软件过程的重要组成部分。达到了每个成熟度等级,就建立了软件过程的不同组成部分,从而使组织的过程能力得到提高
该模型的使用有两种方式:
潜在的客户使用该模型以确定软件供应商的能力和弱点
软件供应商使用该模型以评估自己的能力并找出改进的途径
初始级
初始级描述了一个无序(或混乱)的过程。该过程从输入到输出的转换没有定义且缺乏控制,这使得该过程可见度为零,很难进行全面的度量
由于缺乏适当的结构与控制,即使是相类似的项目也可能在生产率和质量上有很大不同
开发的成功依赖于个人的努力,而不是团队的合作
处于该级别的机构应致力于引入适当的过程结构以及项目管理规程
这个级别没有关键过程域(KPA)
可重复级
确定了过程的输入和输出、约束、资源
具有严格的控制来跟踪成本、进度和功能
小组成员间有一些纪律制度,以便以前的成功项目能在新的类似项目中重复
对需求和产品建立了基线,并控制其完整性
这个等级的关键问题是培训、技术评审、标准
等级2的关键过程域 :
需求管理
软件项目计划
软件项目的跟踪及监督
软件转包合同的管理
软件质量保证
软件配置管理
已定义级
该等级过程中管理和工程活动被文档化、标准化和集成化,形成了对机构中每个人都是标准的一个过程
虽然项目之间可能有所不同,但可以对标准过程进行剪裁从而适应这些特殊需要,而这种修改必需经过管理层的批准
该等级在等级2的基础上提高了过程的可见性,它定义了过程的中间活动,这些活动的输入输出都是已知的、被理解的,从而它们可以被检查、度量和评估,进而可以据此度量产品的属性,并尽可能在过程早期发现和纠正问题
等级3关键过程域:
机构过程关注点
机构过程定义
培训计划
集成软件管理
软件产品工程
开发小组间的协调
同级评审
已管理级
通过对过程和产品质量引入详细的度量,开发机构可以把重点放在使用定量信息以使得问题可见,并评估可能的解决方案的效果
该等级中,反馈决定了资源怎样分配,但并不导致过程的基本活动发生改变
可以对中间活动进行评价,用收集到的度量来稳定过程,以使生产率和质量符合要求
与等级3不同,等级4中的度量反映了总体过程特性、主要活动中及活动之间的交互特性,而度量数据库可以提供有关错误分布、生产率和任务有效性、资源分配等过程特征信息,并比较计划值和实际值匹配的可能性
等级4的关键过程域:
定量过程管理
软件质量管理
优化级
该等级过程中包含了定量的反馈用以产生持续的过程改进
机构能有办法识别过程中的优势和薄弱环节,并预先予以防范
该等级还包括对新的工具和技术进行测试与监控,以了解它们对过程和产品的影响
等级5的关键过程域:
预防故障
技术变更管理
过程变更管理
CMM 的注意事项
成熟度仅表示了从1到5级连续区间中的相对位置,目标是希望软件机构能持续地改进自己的过程,并非要定义五个离散的等级;
改进和评估可以在过程的很多方面同时进行,某些方面可能做得比其它方面更好而超出了当前过程的整体评估等级;
CMM是对软件过程改进领域的重要贡献,但不应该把它视为一种适应所有软件过程的权威性能力模型。不要忽略这个模型设计的初衷:为DoD提供评估软件开发商能力的手段;
开发国防软件与开发商业软件之间有很大不同:
开发非常大型的软件系统出现的问题不一定所有软件机构都能遇到;
商业软件开发需要能更快地响应技术上、业务领域上的变化;
国防软件有一个很长的购买过程和很长的生存期,因此在采用新技术上更趋于保守;