编译原理课程笔记
概论
编程语言的发展:
- 第一代 机器语言: 能够被计算机的硬件系统直接执行的指令程序, 如“
0001000101”。 - 第二代 汇编语言: 将硬件指令用一些助记符表示, 即符号化的机器语言, 如“
ADD,MOV”。 - 第三代 高级语言: 从程序员的角度出发, 对汇编语言进一步抽象, 使用便于理解的“自然语言”表述。
高级语言的实现
编译方式
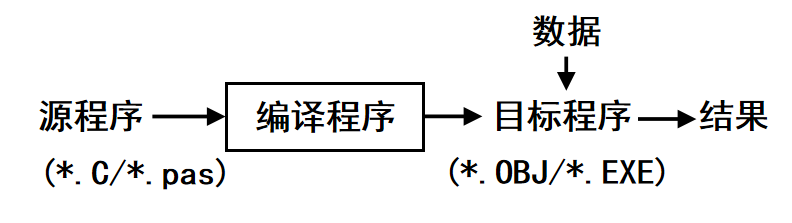
将⾼级语⾔(源语⾔)翻译成低级语⾔(如汇编语⾔或机器语⾔)的⽬标程序的翻译⽅式。⼀次性将源程序翻译为⽬标程序,之后直接运⾏⽬标程序,⽆需重复翻译。
适⽤场景:程序需要频繁运⾏时,编译⽅式更⾼效,因为它省去了反复翻译的过程。
解释方式

逐⾏翻译并同时执⾏⾼级语⾔程序,翻译与执⾏同步完成。⽆需⽣成独⽴的⽬标程序,边翻译边运⾏。
适⽤场景:程序较简单且需要灵活修改时,例如 Excel 表格中的脚本,解释⽅式更具灵活性。
转换方式
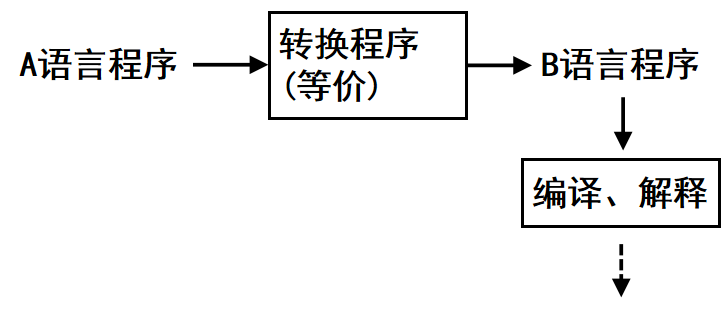
将⼀种⾼级语⾔(A 语⾔)转换为另⼀种⾼级语⾔(B 语⾔),再利⽤ B 语⾔的编译器执⾏。不直接属于⾼级语⾔的实现⽅式,⽽是⼀种变通策略。
适⽤性:依赖已有编译器,适⽤于语⾔间转换的场景。
编译程序的组成
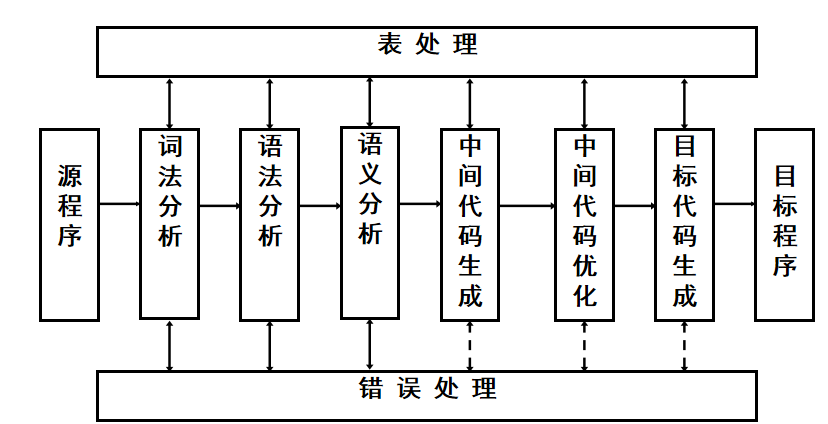
表处理和错误处理也可以算作编译程序的组成部分,但是主要还是中间的六个部分。
词法分析
词法分析器
词法分析器也叫 Scanner,输入是源程序的字符序列,输出是单词序列。它按顺序扫描源程序,识别出具有独立意义的单词,并检查词法错误。
词法分析的输出通常采用二元组形式:<单词类别, 单词内容>。例如:
<保留字, void><界限符, (><保留字, int><标识符, x1><运算符, =><常量, 0>
单词是具有独立含义的最小语义单位。常见单词类型包括保留字、标识符、常量、运算符、界限符、控制符。
实现词法分析器的基本步骤:
- 明确要识别的单词类型和词法规则。
- 使用形式化方法描述各类单词,主要工具是正则表达式和自动机。
- 根据描述设计词法分析算法。
符号和符号串
字母表是元素的非空有穷集合,通常记为 。字母表中的元素称为字母、符号或字符。
例如:
符号串是由字母表中的符号组成的有穷序列,也称字符串或句子。常用 表示。
长度
符号串长度表示为 。空串记为 ,其长度为 。
连接
若 和 都是 上的符号串,则它们的连接记为 。例如 ,,则 。
连接满足:
方幂
符号串的方幂表示重复连接。若 是符号串,则:
符号串集合是由某个字母表上的符号串组成的集合。若 和 是两个符号串集合,则它们的乘积定义为:
例如 ,,则:
符号串集合的方幂定义为:
若 ,则:
正闭包表示一次或多次连接:
星闭包表示零次或多次连接:
也可写为:
例如 letter 表示所有英文字母,则 表示所有非空英文字符串, 表示包含空串在内的所有英文字符串。
正则表达式
正则表达式是描述正则集的一种代数表达式,也称正规表达式。它使用预先定义的符号和运算规则构造模式,用来描述一类字符串。
正则表达式 所描述的符号串集合称为正则集或正规集,记为 ,也称为由 定义的语言。语言就是字母表上字符串的集合。
例如:
这个表达式可描述十进制非负整数。
设 为字母表,正则表达式递归定义如下:
和 是 上的正则表达式:
对任意 , 是 上的正则表达式:
若 和 是正则表达式,则以下表达式也是正则表达式:
它们对应的语言为:
正则表达式中的主要运算:
- 括号
( ):确定运算优先级 - 或运算
|:表示多个模式的并集 - 连接运算
·:表示前后相邻部分的组合,实际书写中常省略 - 闭包运算
*:表示零次或多次重复
实际应用中还常使用正闭包 +:
运算优先级为:
例如 ab* 表示先对 b 做闭包,再与 a 连接,即 。
正则表达式描述单词
正则表达式可用于化简和构造词法规则。
交换律:
结合律:
分配律:
幂等律:
同一律:
例如在字母表 上:
ab* 表示所有以 a 开头,后面跟零个或多个 b 的字符串,即:
a(a|b)* 表示所有以 a 开头,后面跟任意个 a 或 b 的字符串。
整数可用正则表达式描述。设:
则:
- 表示允许前导
0的数字串 - 表示无符号正整数
- 表示带符号整数和
0 - 表示整数
词法分析中常见单词的正则描述:
保留字:
1 | |
标识符:
其中:
整数常量:
其中:
实数常量:
特殊符号包括:
- 运算符:
+|-|*|... - 分界符:
{|}|;|... - 控制符:
\t|\n|...
这几部分的核心关系是:词法分析器要识别源程序中的单词,符号串理论提供基本对象,正则表达式提供形式化描述,单词规则可用正则表达式精确表示。
正则表达式的局限性

注意事项
有大括号的是集合。正则表达式是用上面的运算得到的式子。
例题:设字母表 ,求为 2 的倍数的二进制数字符串集合。
表示任意字串,那么答案应该是 。
例题:

- 可以构造成
- 可以构造成
确定有限自动机 DFA
有限自动机 FA 是一种字符串识别装置,可以识别正规集。词法分析中引入 FA,是为了给词法分析程序的自动构造提供形式化工具。
有限自动机分为两类:
- 确定有限自动机 DFA:Deterministic Finite Automata
- 非确定有限自动机 NFA:Nondeterministic Finite Automata
DFA 定义为一个五元组:
其中:
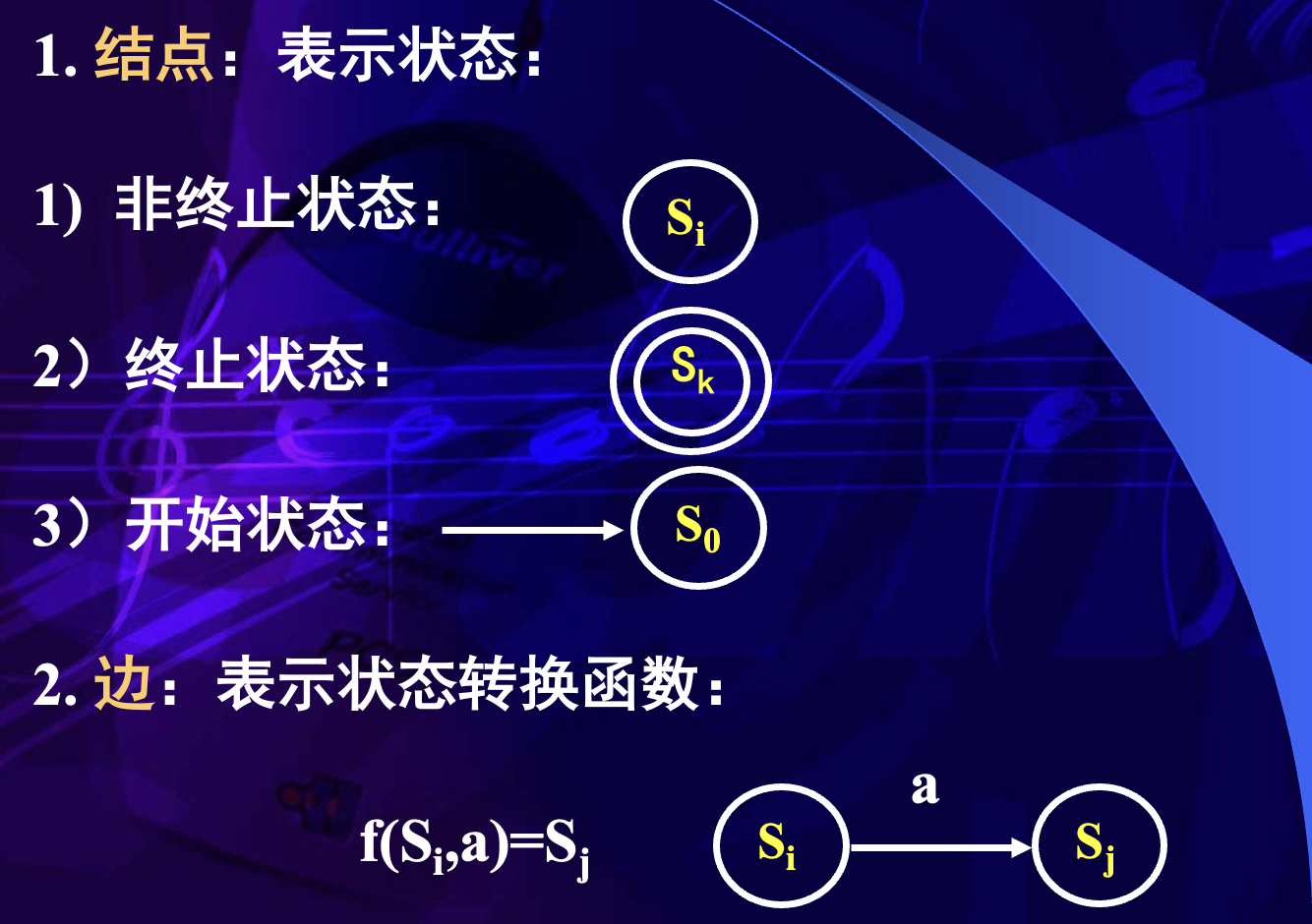
- 是有穷状态集,其中每个元素称为一个状态
- 是有穷字母表,其中每个元素称为输入字符
- 是唯一初始状态,也称开始状态
- 是状态转换函数,
- 是终止状态集,也称可接受状态集或结束状态集
状态转换函数 表示:当前状态为 ,读入输入字符 a 时,自动机唯一转换到状态 。 称为 的一个后继状态。
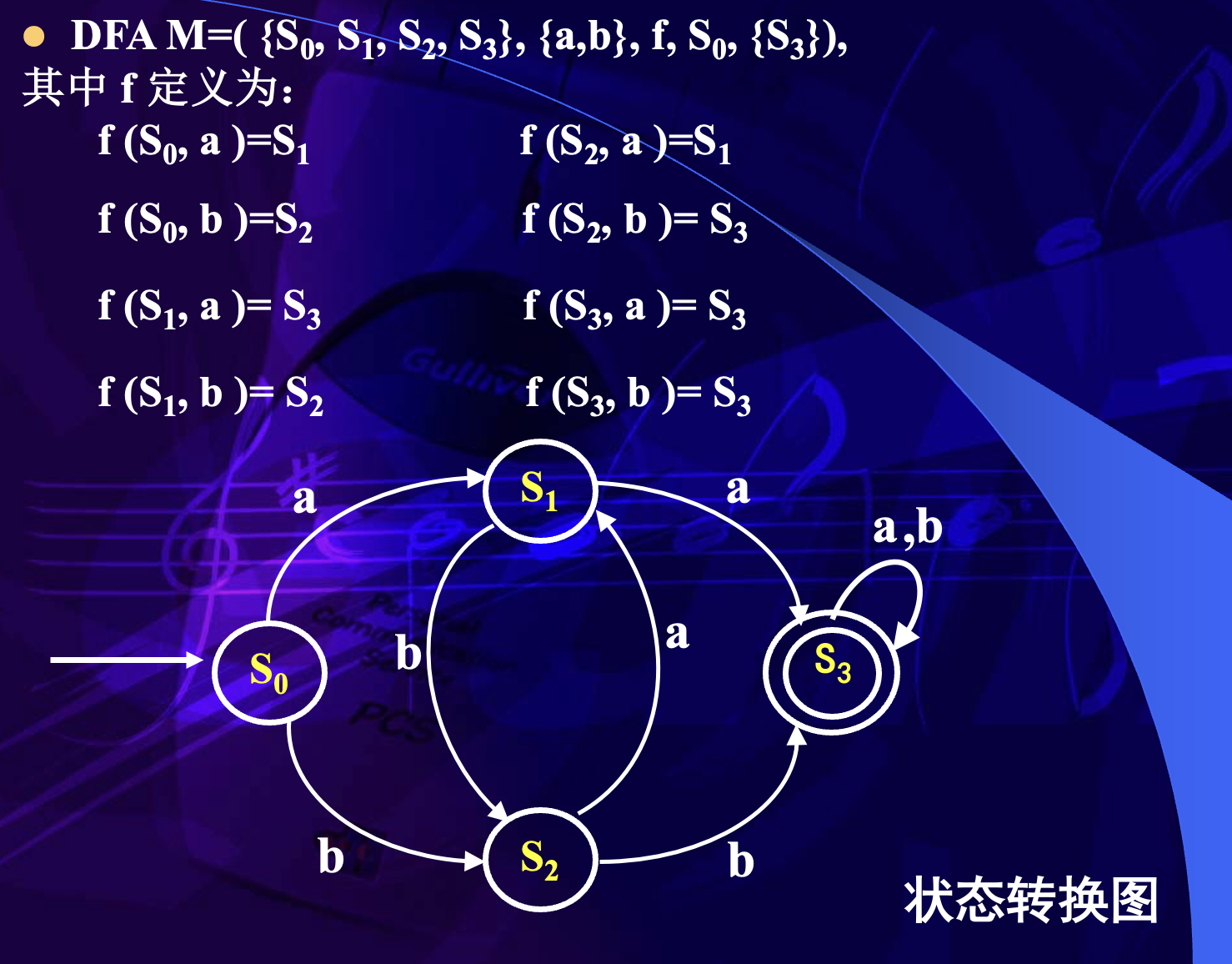
例如:
其中转换函数为:
这个 DFA 的初始状态是 ,终止状态是 ,输入字母表是 。
DFA 的表示方式
DFA 有两种常见表示方式。
第一种是状态转换图。状态转换图使用有向图表示自动机:
第二种是状态转换矩阵。矩阵中:
- 行表示状态
- 列表示输入字符
- 矩阵元素表示转换后的状态
- 初始状态常用
+标记 - 终止状态常用
*或-标记
以上面的 DFA 为例,状态转换矩阵为:
| 状态 \ | ||
|---|---|---|
陷阱状态
陷阱状态是自动机进入错误路径后的状态。进入陷阱状态后,后续任意输入通常都停留在陷阱状态中。
例如某 DFA 中:
其中状态 4 就是陷阱状态,因为读入 a 或 b 都回到 4。
DFA 的确定性体现在三个方面:
- 初始状态唯一
- 对任何状态 和输入符号 , 唯一
- 状态转换依赖输入字符,DFA 中每一步都有确定的后继状态
- 的输入为空边,也就是不接受没有任何输入就进行状态转换的情况
DFA 接受的字符串
对于字母表 上的任意字符串 ,若 DFA 中存在一条从初始状态到某个终止状态的路径,并且路径上所有边的标记依次连接后等于 ,则称该字符串可被 DFA 接受或识别。
形式上说,DFA 处理字符串时,从初始状态开始,按字符顺序读取输入,每读入一个字符就根据状态转换函数移动到下一个状态。输入读完后,若当前状态属于终止状态集 ,则该字符串被接受。
DFA 能接受的所有字符串构成的集合,称为 DFA 接受的语言,记为 。
例如某 DFA 的路径可识别形如 aba(ab)* 的字符串,则:
aba可被接受abaab可被接受abaabab可被接受abaa根据最终状态判断- 是否被接受取决于初始状态是否为终止状态
DFA 的应用包括:
- 在语言学中,自动机可作为语言识别器
- 在计算机科学中,自动机可作为计算过程的动态数学模型
- 在自动控制领域中,自动机可处理控制信号序列
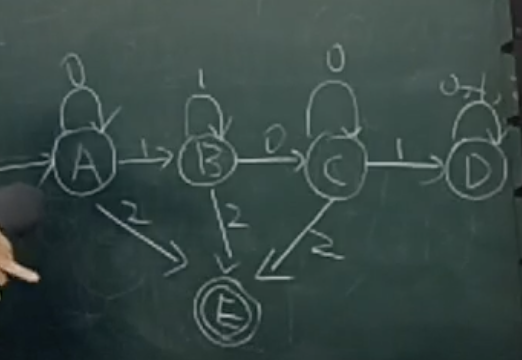
设计识别能被 3 整除的二进制数的 DFA 时,可用余数作为状态:
- :当前二进制数除以
3余0 - :当前二进制数除以
3余1 - :当前二进制数除以
3余2
初始状态是 ,终止状态也是 。因为余数为 0 表示该二进制数能被 3 整除。
读入一个新二进制位 b 后,原数 变为 ,新余数为:
其中 是原来的余数,。
因此转换规律为:
| 状态 \ | ||
|---|---|---|

这个 DFA 可以画成下面的图,其中 D 是个非法状态:
DFA 描述单词
DFA 可以用来描述词法分析中的各种单词。
标识符的描述,设:
标识符的正则表达式为:
对应 DFA 的含义是:第一个字符必须是字母或下划线,后续字符可以是字母、下划线或数字。常数等的命名规则同上。
这些表达式可转成 DFA,用状态表示是否已经读入符号、整数部分、小数点和小数部分。
特殊符号也可由 DFA 描述。例如 {、+、>、= 都可以从初始状态读入单个字符后进入对应终止状态。若要识别复合运算符,例如 >=,则读入 > 后需要继续判断下一个字符是否为 =。
保留字可用字符路径描述。例如 for 的 DFA 路径为:
1 | |
其中状态 3 是接受状态。
if 的 DFA 路径为:
1 | |
其中状态 5 是接受状态。
实际词法分析中,保留字和标识符容易冲突。常用处理方法是先按标识符规则识别完整字符串,再查保留字表。若识别到的字符串是 if、for、while 等,则输出保留字类别;否则输出标识符类别。
DFA 的程序实现
DFA 的程序实现主要有两种方法。
第一种是直接转向法。它基于状态转换图实现,每个状态对应一段 switch 判断,不同输入字符跳转到不同状态。
示意代码:
1 | |
直接转向法的特点是:程序结构与状态图一一对应,理解直观;当状态图变化时,代码也要跟着变化。
第二种是基于状态转换矩阵的方法。它把 DFA 存成表,通过查表完成状态转换。
示意代码:
1 | |
其中:
state表示当前状态curChar表示当前输入字符T[state][curChar]表示状态转换矩阵FinalState表示终止状态集合#表示输入结束符
状态转换矩阵法的优点是程序框架固定,只需要修改状态表即可适配不同 DFA。它适合词法分析器的自动生成。状态较多、字符集较大时,矩阵可能占用较多存储空间,可使用压缩表或稀疏表优化。
NFA 的确定化
NFA,即非确定有限自动机,是一个五元组:
其中:
- :有穷状态集
- :输入字母表
- :状态转换函数,
- :初始状态集
- :终止状态集
含义是:NFA 在某个状态读入一个字符,或通过 空边,可以转移到一个状态集合。它允许一个状态对同一输入有多个后继状态,也允许 转移。

自动机等价的定义:设 和 是同一个字母表 上的自动机,若它们接受的语言相同,即:
则称 和 等价。
重要定理:对任意一个 NFA ,都存在一个 DFA ,使得:。
由 NFA 构造与其等价的 DFA 的过程,称为 NFA 的确定化。
NFA 确定化的核心方法是子集法。它的思想是:DFA 的一个状态记录 NFA 在读入某个输入符号后可能达到的一组状态。也就是说,NFA 中的一组状态:
可以作为 DFA 中的一个状态 。

无 空边 NFA 的确定化
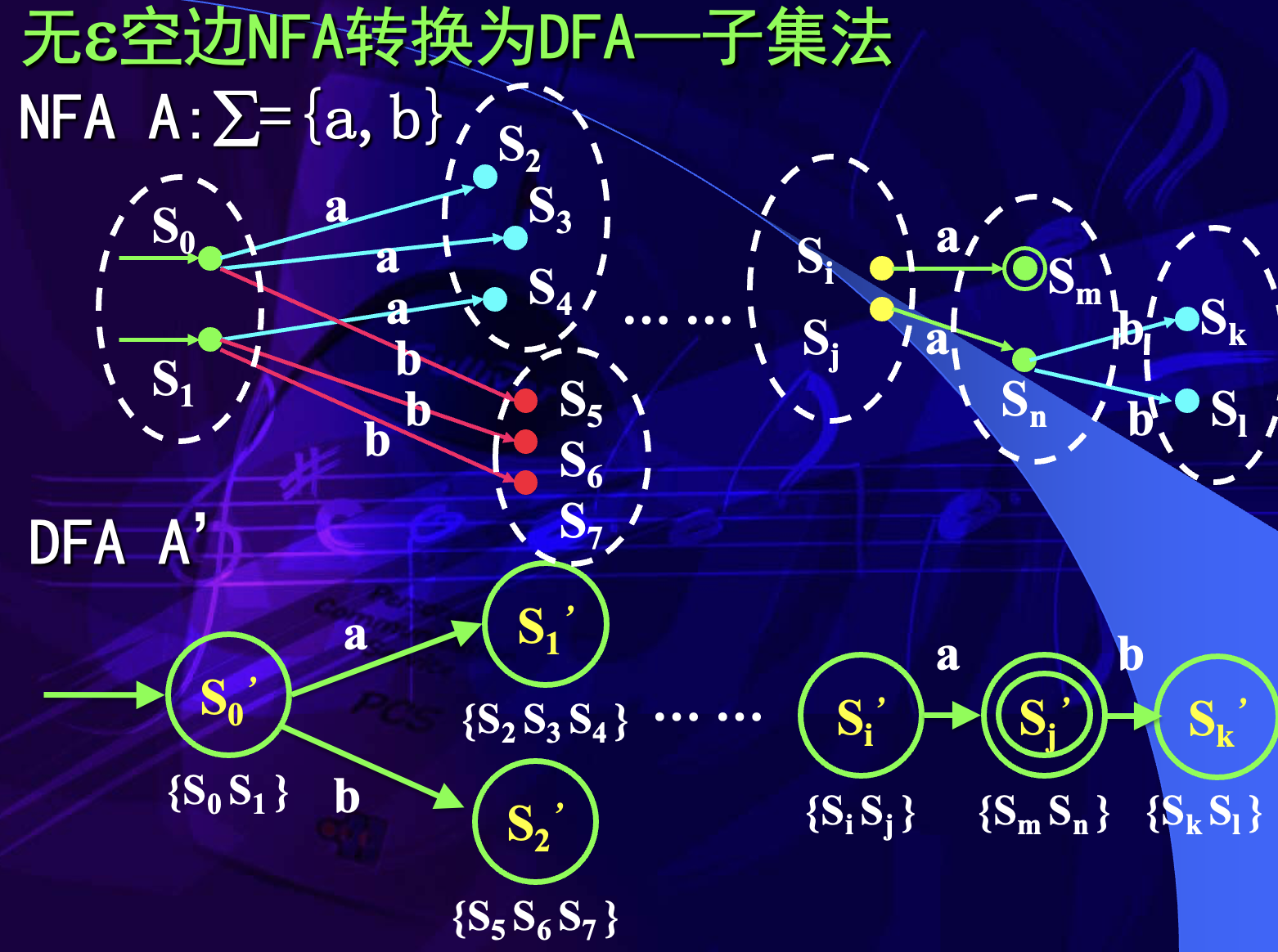
对于无 空边的 NFA,确定化时直接计算状态集合在每个输入符号下能到达的新状态集合。
设当前 DFA 状态对应 NFA 状态集合 ,输入字符为 ,则新状态集合为:
每得到一个新的状态集合,就把它作为 DFA 的一个新状态,继续对所有输入符号求转换,直到没有新状态集合产生。
带 空边 NFA 的确定化
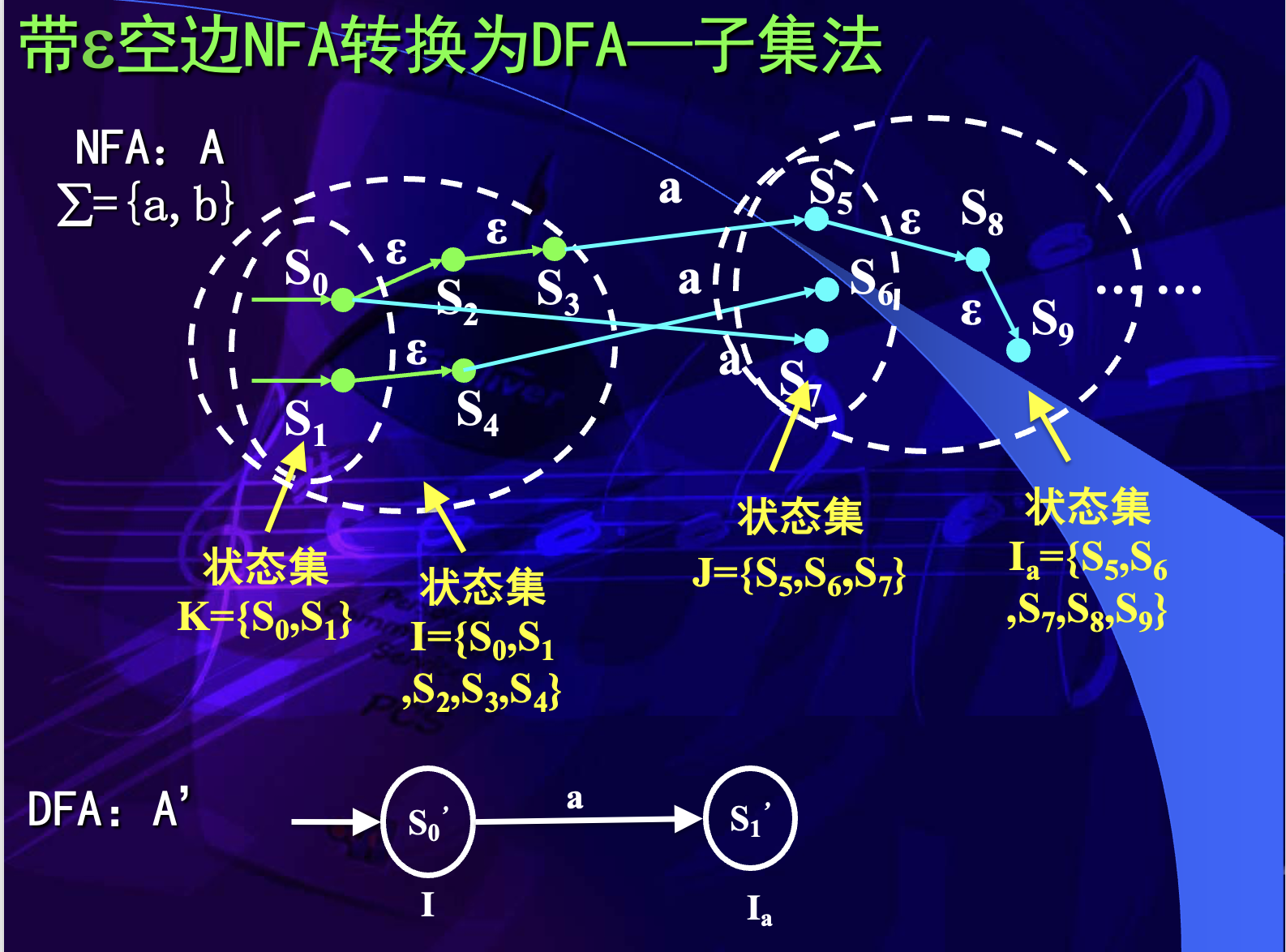
带 空边时,需要先引入 闭包。状态集 的 闭包记为:
定义如下:
- 若 ,则 。
- 若 ,并且从 出发经过任意条 边可到达 ,则 。
设 是 NFA 的一个状态集合,对输入字符 ,先求:
再求:
其中 就是状态集 读入 a 后在 DFA 中应转移到的新状态集合,它也是闭包。
完整确定化流程:
- 求 NFA 初始状态集的 闭包,作为 DFA 初始状态。
- 对每个 DFA 状态集合 ,分别计算每个输入字符下的 。
- 若 是新的状态集合,则加入 DFA 状态集。
- 重复计算,直到状态集合不再增加。
- 若某个 DFA 状态集合中包含 NFA 的终止状态,则该 DFA 状态是终止状态。
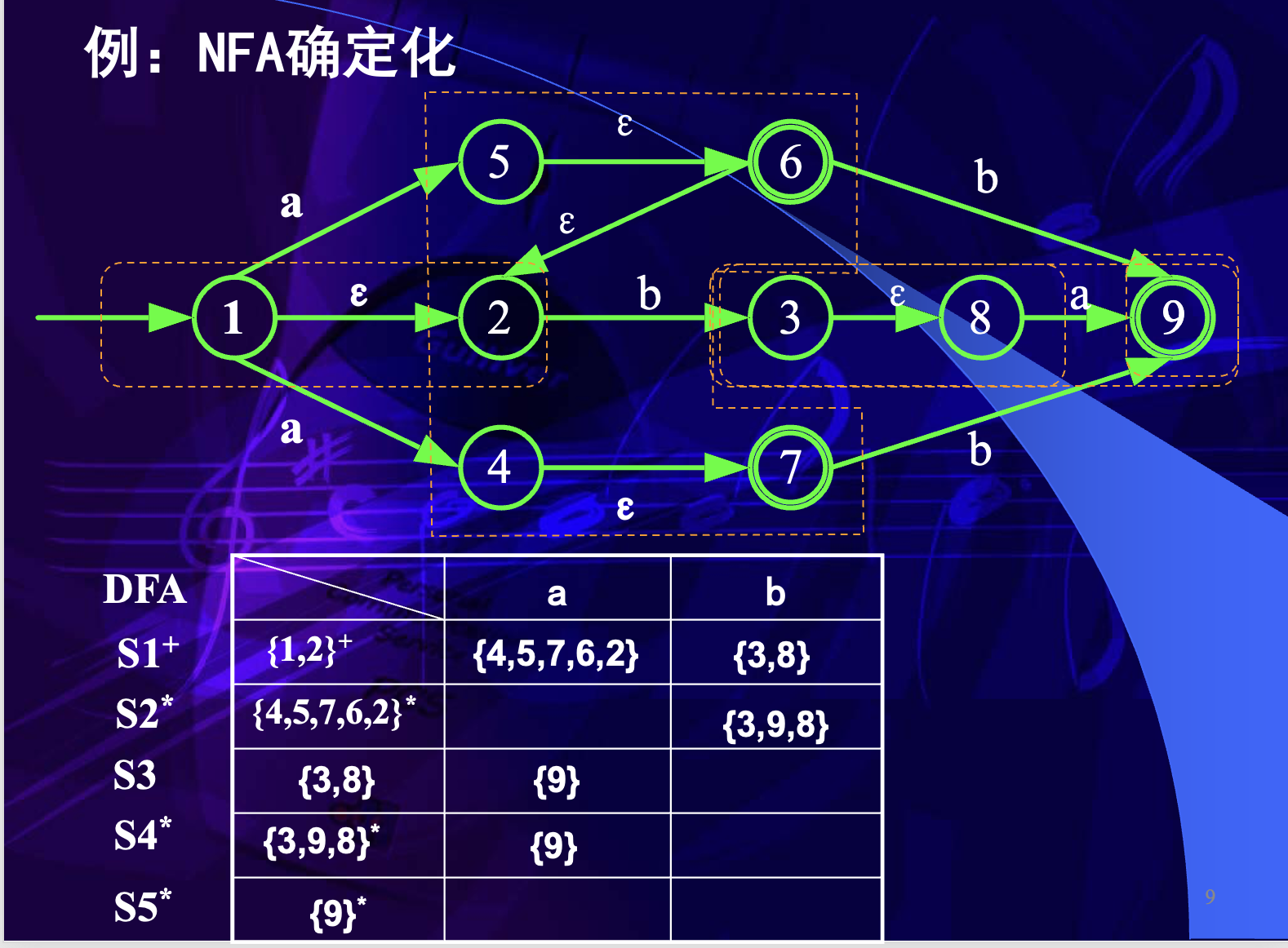
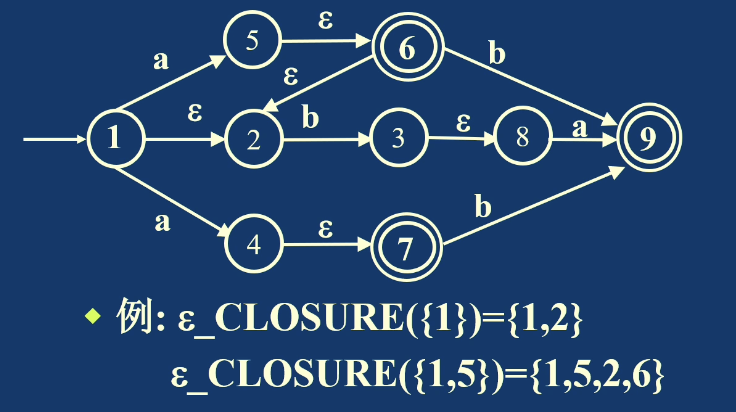
课件中的例子把 NFA 状态集合转换为 DFA 状态,例如:
其中包含 NFA 终态 9 的集合,对应 DFA 的终止状态。
NFA 的终态是人为规定的,只要包含 NFA 的任意一个终态,那么 DFA 的对应状态也是终止状态。
另一个例题:
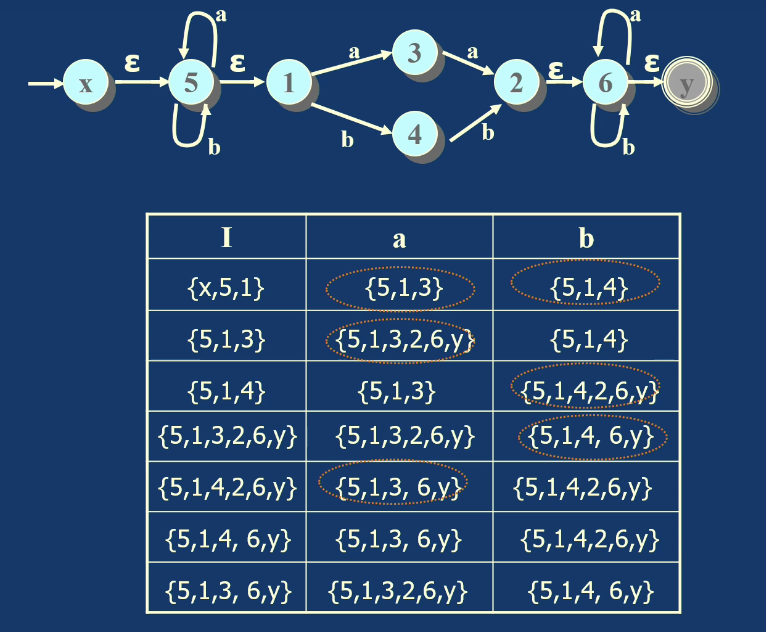
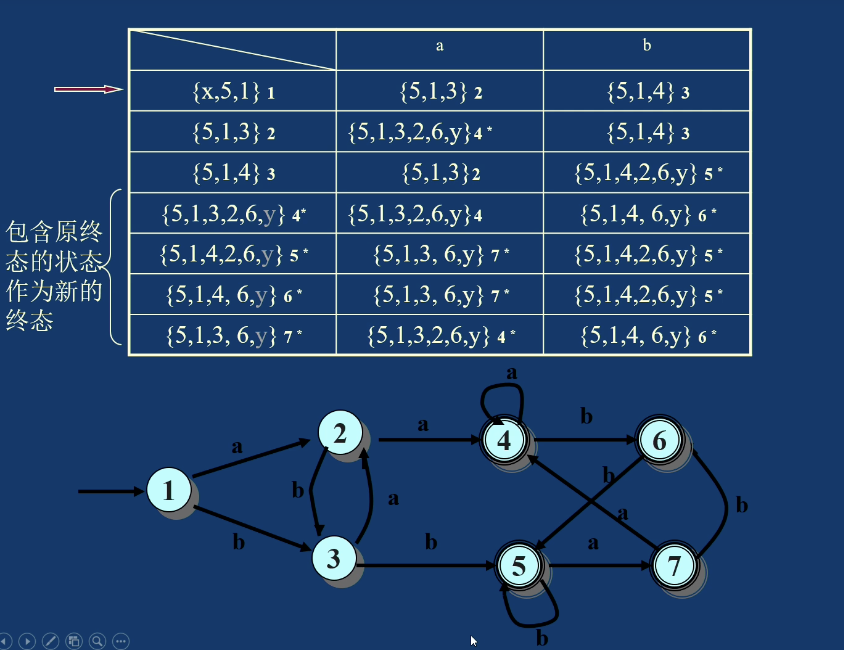
NFA 确定化的本质是把“多种可能路径同时存在”的情况压缩进 DFA 的一个集合状态中。每个集合状态代表 NFA 当前可能处于的所有状态。
DFA 的化简
DFA 化简的目标是得到最小自动机。最小自动机的定义是:DFA 中没有无关状态,也没有等价状态。
无关状态
状态 是无关状态,通常有两种情况:
- 从开始状态没有到 的通路。
- 从 出发没有到任意终止状态的通路。
这类状态对识别语言没有实际贡献,可以删除。
等价状态
对 DFA 中两个状态 和 ,若分别把它们看作初始状态时,能接受的符号串集合相同,则称 和 等价。
状态等价需要满足两个条件:
- 一致性条件: 和 同时为接受状态,或同时为非接受状态。
- 蔓延性条件:对所有输入符号, 和 都必须转换到等价状态中。
也就是说,若输入字符为 ,则 和 也应等价。
终止状态和非终止状态属于不同类别,二者在初始划分时分开。
状态分离法
DFA 化简常用状态分离法。步骤:
- 初始划分:把所有终止状态分为一组,所有非终止状态分为一组。
- 检查每一组中的状态:若它们对某个输入字符转向不同的组,则这些状态应被分离。
- 得到新分组后继续检查。
- 重复分离,直到没有新组产生。
- 每个最终分组中的状态互相等价,可以合并为一个状态。
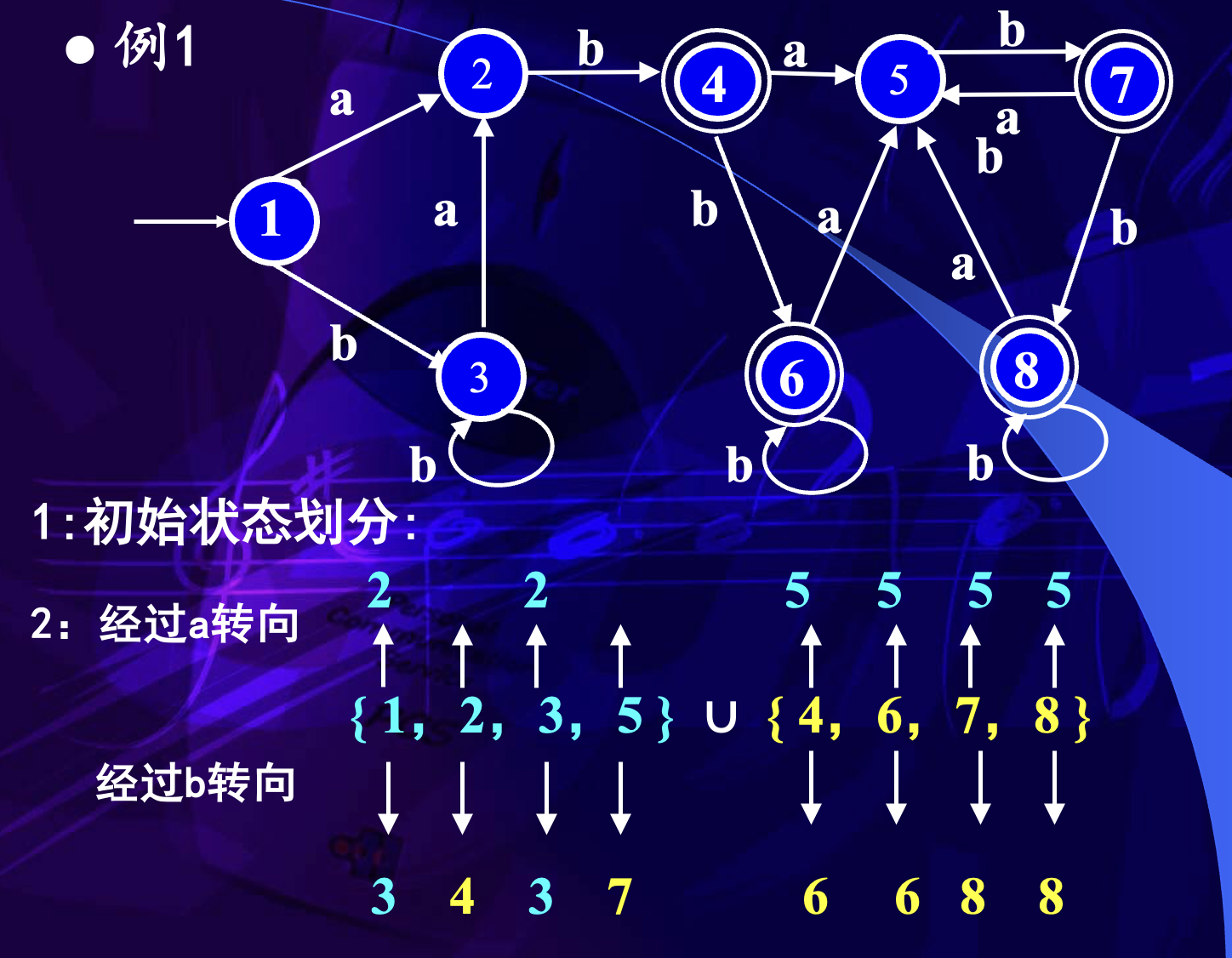
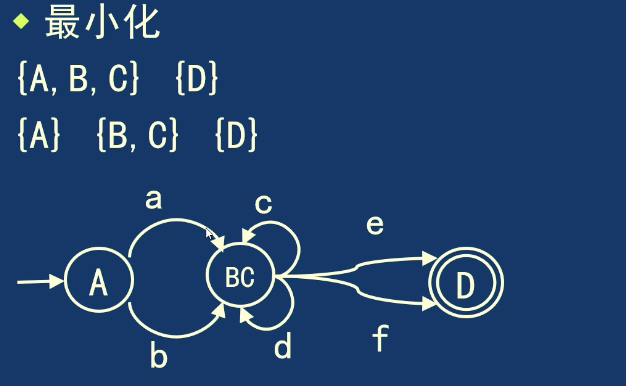
课件例子中的初始划分为:
经过输入字符 a 和 b 的转向检查后,进一步分离为:
最终化简后,这三个状态集合分别合并为三个新状态:
DFA 化简的关键判断是:同组状态在每个输入字符下的后继状态是否仍然落在相同分组中。若转向模式相同,则这些状态保留在同组;若转向模式不同,则继续拆分。
正则表达式和有限自动机的相互转化
正则表达式和有限自动机描述能力等价。对 上的每一个正则表达式 ,都存在一个 上的 NFA ,使得:
因此,正则表达式可以转为 NFA,NFA 也可以转为等价的正则表达式。
正则表达式到 NFA
正则表达式到 NFA 的转换基于基本结构组合。
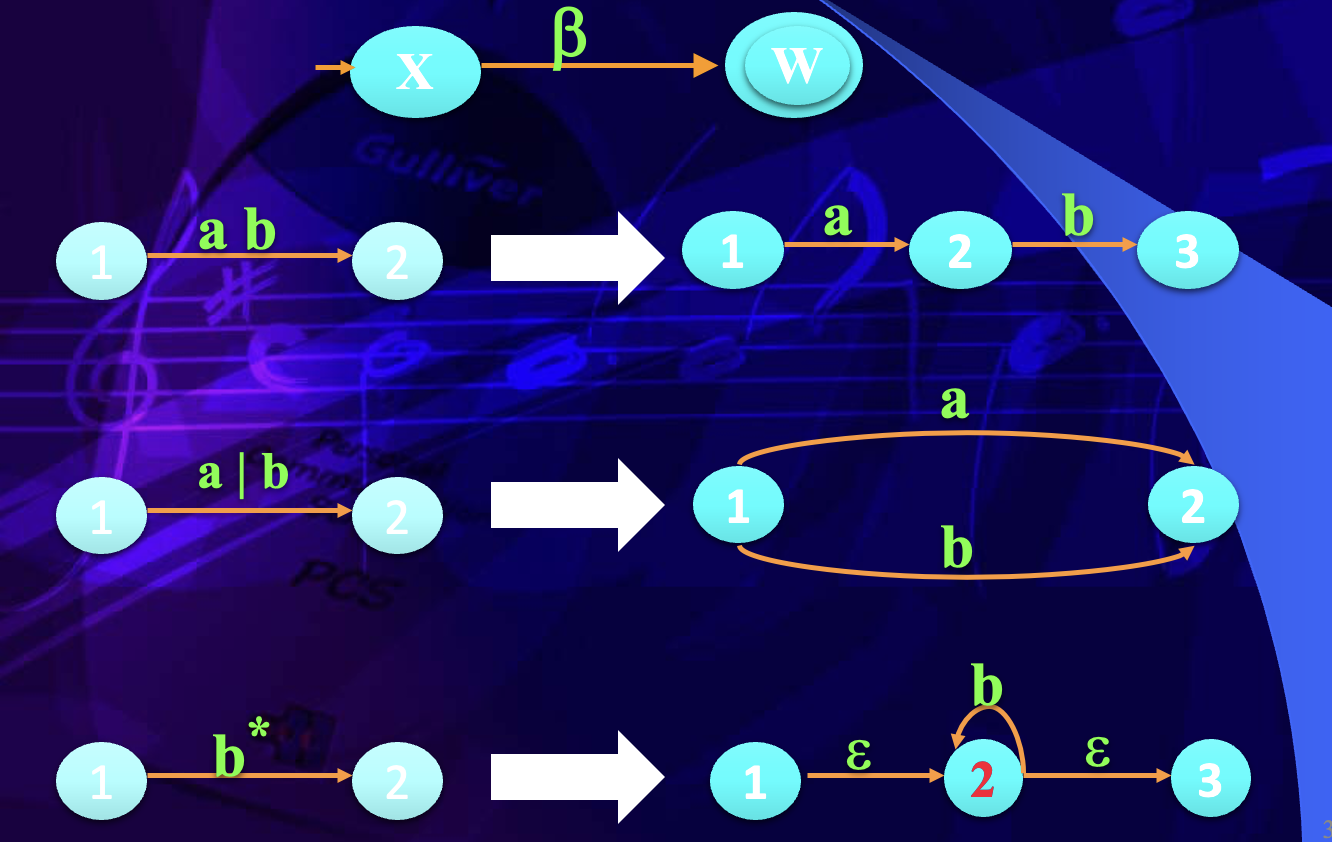
- 单个字符
a:构造一条从开始状态到终止状态、标记为a的边。 - 连接表达式
ab:先构造a的 NFA,再构造b的 NFA,把前一个片段的终止状态连接到后一个片段的开始状态。 - 或表达式
a|b:从新开始状态通过 边分别进入a和b的子自动机,再通过 边汇合到新终止状态。 - 闭包表达式
b*:构造b的子自动机,并加入 边,使其可以重复执行,也可以直接从开始状态到终止状态。
课件例子:为正则表达式 (a|b)*aa 构造 NFA。
拆分结构为:
1 | |
再继续拆为:
1 | |
构造思路:
- 先构造
a|b的分支结构。 - 对
a|b加*,形成(a|b)*的循环结构。 - 后面依次连接两个
a。 - 得到接受所有以两个
a结尾、前面由任意个a或b组成的字符串的 NFA。
该表达式对应的语言可以理解为:
即所有字母表 上以 aa 结尾的字符串。
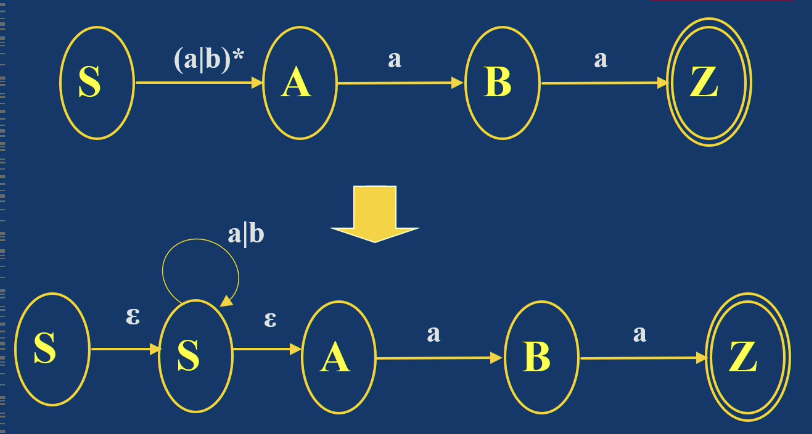
NFA 到正则表达式
NFA 到正则表达式的转换可通过逐步消去状态完成。基本思想是把经过中间状态的路径合并为一个正则表达式标记。
常见合并规则:
- 多条并行边合并为或表达式,例如
a和b合并为a|b - 连续路径合并为连接表达式,例如
a后接b合并为ab - 自环合并为闭包表达式,例如状态上有
a自环,可形成a* - 经由某个中间状态的路径可合并为“进入路径 + 自环闭包 + 离开路径”
课件例子中,NFA 逐步消去中间状态后得到正则表达式:
这个表达式表示:
- 字符串以
a开始。 - 中间接
ab或ba。 - 后面接零个或多个
a。 - 最后以
b结束。
例题:构造 的最简 DFA
目标正则表达式:
它描述的字符串结构为:
- 第一个字符是
a或b。 - 中间可以有零个或多个
c或d。 - 最后一个字符是
e或f。
第一步:转为 NFA。
结构可分为三段:a|b、(c|d)*、e|f
NFA 中先通过 a 或 b 进入中间部分,中间部分在 c 和 d 上循环,最后通过 e 或 f 到达终止状态。
第二步:NFA 确定化。
课件给出的 DFA 状态集合包括:
其中 是初始状态, 是终止状态。
对应转换表可整理为:
| 状态 | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
第三步:DFA 最小化。
初始划分:
进一步判断后得到等价状态:
因此 和 可以合并。
最简 DFA 的结构为:
- 初始状态
- 中间状态
- 终止状态
转换关系:
- 读入
a或b到达 - 读入
c或d仍留在 - 读入
e或f到达
第 9 到第 11 部分可以串成一条完整流程:先把 NFA 通过子集法确定化为 DFA,再用状态分离法化简 DFA;正则表达式可先转 NFA,再确定化、化简,最终得到可直接实现的最简 DFA。
语法分析
文法
文法是描述语言语法结构的形式化工具。一个文法定义为四元组:
其中:
- 是终结符集合
- 是非终结符集合
- 是开始符号,且
- 是产生式集合
产生式的一般形式是:
其中 ,并且左部通常至少要包含非终结符[1]。书写时通常只写产生式集合;若多个产生式左部相同,可以合并书写,如 。
文法的分类
按乔姆斯基层次,文法可以分为四类:
0型文法:短语文法,产生式一般写作 $ \alpha \to \beta $,左部至少包含一个非终结符1型文法:上下文有关文法,满足 ,也就是表达式的长度不缩短,一般的形式是 ,但开始符相关情况有例外2型文法:上下文无关文法 CFG,产生式左部只能是一个非终结符3型文法:正则文法,右部最多两个符号,通常形如 或
这一章后续的语法分析主要围绕 CFG 展开。
上下文无关文法 CFG
上下文无关文法仍然写作:
但其产生式必须满足:
其中 ,每个 ,右部允许为空,即可以出现 。例如:
这是一个典型的 CFG。
推导、句型、句子与语言
如果有产生式 ,那么对于任意符号串 ,都有一步推导:
这里:
- 表示经过一步或多步推导得到
- 表示经过零步或多步推导得到
若有:
则称 是文法的句型。若 只包含终结符,则称 是句子。
文法定义的语言记为:
也就是从开始符号出发能够推导出的所有终结符串的集合。
最左推导、最右推导与句柄
若每一步总是替换当前句型中最左边的非终结符,则称为最左推导。若总是替换最右边的非终结符,则称为最右推导。
- 最左推导得到的中间结果称为左句型
- 最右推导得到的中间结果称为右句型,也叫规范句型
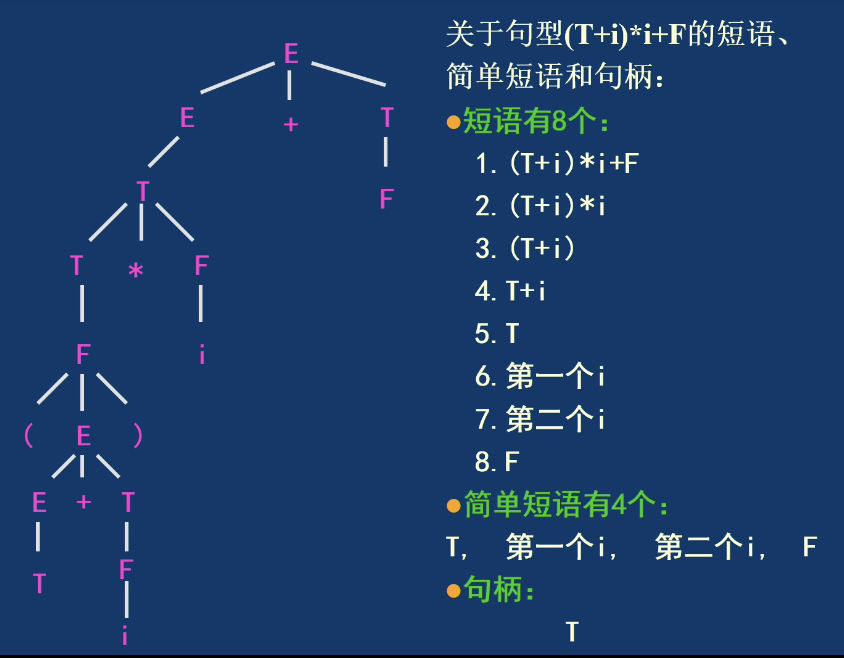
一个句型中的某个子串若是由某个非终结符推导出来的,就称它为该句型的短语。若这个推导只用一步完成,则称为直接短语。一个句型中最左边的直接短语叫句柄。
句柄在自底向上分析里很关键,因为归约时通常就是在找句柄。
语法分析树
语法分析树是句型结构的树形表示。它满足:
- 根结点是开始符号
- 非叶结点标记非终结符
- 叶结点标记终结符、非终结符或
- 若某个非叶结点标记为 ,其孩子从左到右为 ,则文法中必须有产生式:
语法分析树描述的是结构,线性推导描述的是推导顺序。一个句型若文法无二义性,通常对应唯一分析树;线性推导过程可能不止一种。

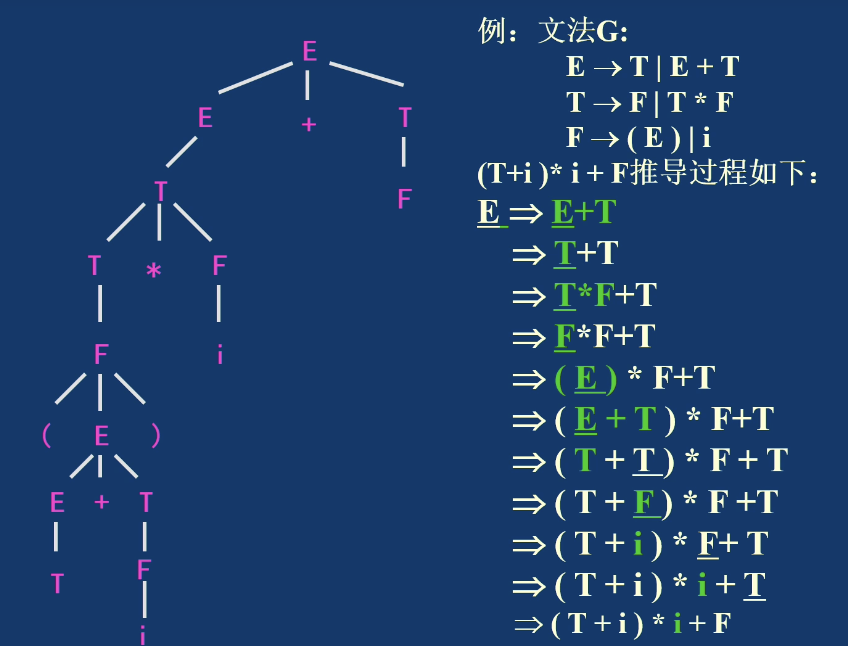
例题:
二义性文法
若一个文法的某个句型有两棵不同的语法分析树,则该文法是二义性文法。
等价地说,若某个句型存在两种不同的最左推导或两种不同的最右推导,该文法也是二义性的。
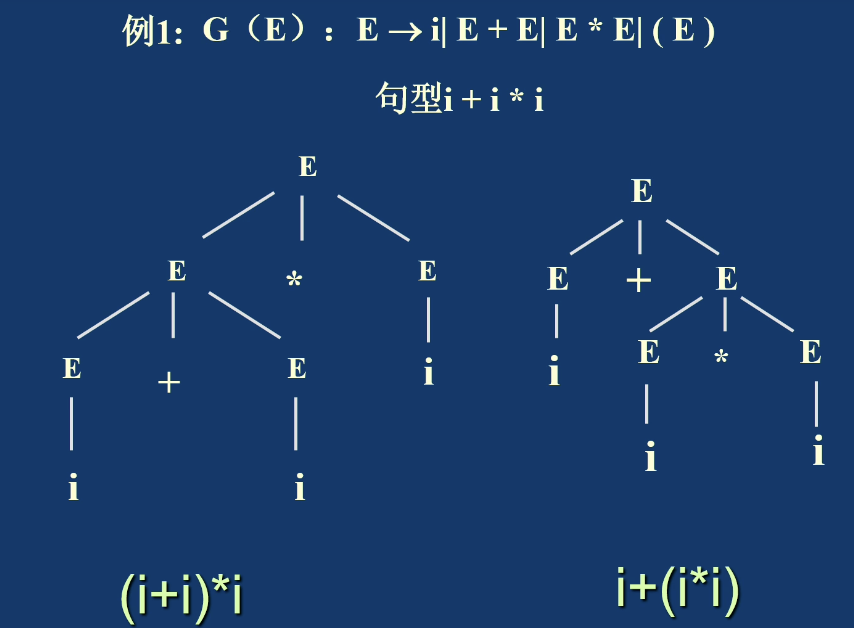
例如表达式文法:
对串 i*i+i 可以构造两种不同结构的分析树,因此它是二义性文法。二义性会直接影响语法分析器如何确定结构。
另一个例子:

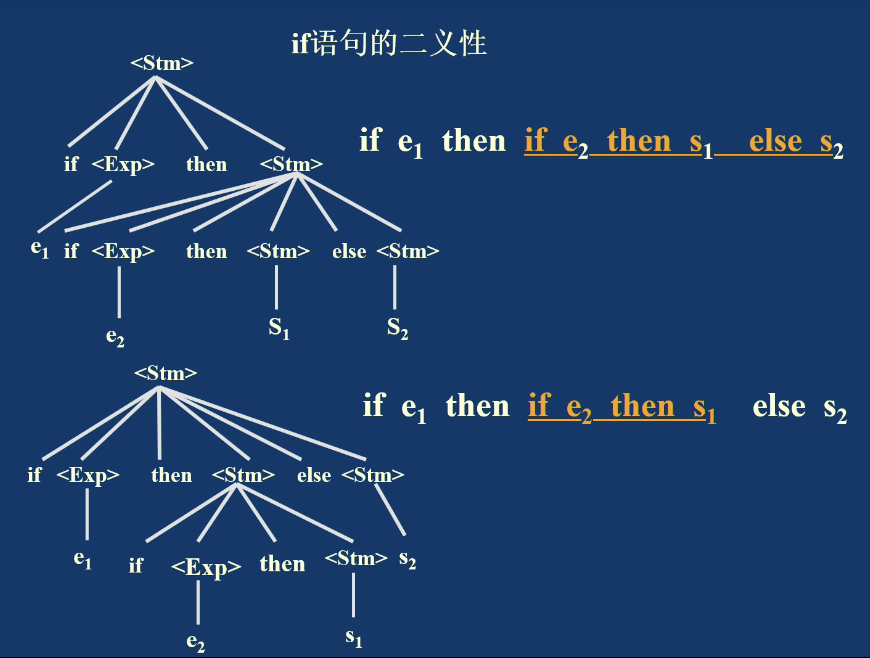
在 C 语言中,else 会和最近的 if 匹配。
目前没有一般性的判断二义性的方法。
常用的经验性判断:
- 可以推导出 串,必有二义性
- 可以推导出 ,必有二义性
因为递归结构没有规定结合方向。 可以左结合或右结合, 也可以左结合或右结合,所以会出现两棵语法树。实际写文法时,可以通过分层或固定递归方向消除这类二义性。
文法等价变换
文法等价变换的目标是:在不改变语言 的前提下,把文法改写成更适合语法分析的形式。后面的递归下降和 LL(1) 分析都依赖这一步。
增加拓广产生式
对任一文法 ,都可以构造等价文法 ,使其开始符唯一且不出现在任何产生式右部。
方法是:若原开始符号为 ,引入新开始符号 ,增加一条产生式:
例如原文法 $ A \to aA \mid b $,可拓广为:
- $ A \to aA \mid b $
这一步常用于后续构造分析器或分析表。
消除空产生式
空产生式是形如:
的产生式。消除空产生式的核心思路是先找出所有能推出 ε 的非终结符,再把这些符号在其他产生式右部中“可有可无”的情况补出来,最后删除空产生式。
课件中的方法可以压成三步:
- 求出所有可空非终结符集合
- 对含这些符号的产生式补充删去相应符号后的新产生式
- 删除原空产生式及只能导出空串的无用部分
例如文法:
A -> aBcDB -> b | εD -> BB | d
其中 B 可空,D 也因此可空。补充规则后,可得到:
A -> aBcD | acD | aBc | acB -> bD -> BB | B | d
这样语言保持不变,但文法中已经没有空产生式。
消除不可达产生式
若某个非终结符从开始符号出发永远不会在任何句型中出现,则它是不可达的。以它为左部的产生式对语言没有贡献,可以删掉。
算法思路:
- 从开始符号出发,放入可达集合
- 扫描所有已可达非终结符的产生式右部,把能到达的新非终结符继续加入
- 重复直到集合不再变化
- 删除左部不在该集合中的所有产生式
这一步是在去掉“永远用不到”的规则。
消除特型产生式
特型产生式指形如:
的单非终结符产生式,也就是右部只有一个非终结符。它会让推导链变长,不利于后续分析。
处理思路:
- 对每个非终结符 ,求出所有能由 到达的非终结符集合
- 若这些 有非特型产生式 ,则把 补进来
- 删除所有特型产生式
- 再删一遍不可达产生式
例如:
A -> B | D | aBB -> C | bC -> cD -> B | d
消除后可整理为:
A -> aB | b | d | cB -> b | c
消除公共前缀
若某个非终结符有多个候选式以同样的前缀开头,就存在公共前缀。例如:
这种文法在自顶向下分析时,读到前缀 仍然无法决定选哪条产生式,所以要提取左因子。
方法是引入新非终结符 ,改写为:
- $ A \to \alpha A’ \mid \gamma $
本质上是把“共同开头”先抽出来,再延后分支选择。

消除左递归
左递归会导致递归下降分析器无限递归,因此必须消除。
若文法存在:
则称文法有左递归。

直接左递归
形如:
可改写为:
这个改写把“反复重复 ”转到新非终结符 中。
间接左递归
例如:
需要先代入,把它变成直接左递归形式,再按直接左递归的方法消除。课件给出的思路是先展开成类似:
$ A \to A\gamma\alpha \mid b\alpha \mid \beta $
或对 做同类替换,然后再套直接左递归消除公式。
例题:构造一个文法 ,使 。
构造如下:

可以这样构建:
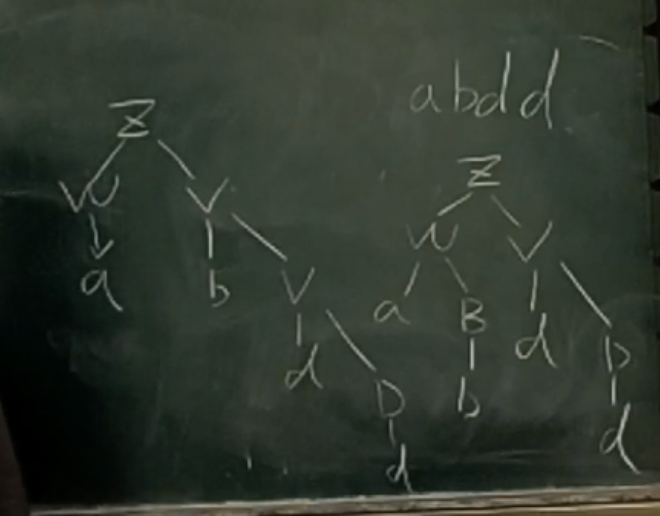
所以它是一个二义性的文法。
语法分析的功能
语法分析的任务是按照程序设计语言的语法规则,识别并分解程序中的各种语法成分。它要解决的核心问题是:给定文法 和输入串 ,判断 是否是 所能生成的句子。
在编译过程里,语法分析位于词法分析之后、语义分析之前。词法分析把源程序切分成 token 串,语法分析根据这些 token 构造语法结构,通常产出语法树或语法分析树,供后续语义分析使用。
语法错误处理
语法分析不仅要判断“对不对”,还要在出错时尽量继续工作。要求有三个:
- 报告错误出现的位置
- 尽量修复错误并继续检查后续部分
- 处理代价不能过大
常见错误处理策略有四种。
紧急方式恢复
发现错误后,分析器不断丢弃输入符号,直到当前输入符号属于某个同步记号集合。这样可以尽快跳到一个相对安全的位置继续分析。
这种方法实现简单,代价较低,但可能跳过较多内容。
短语级恢复
发现错误后,对剩余输入串的前缀做局部修正,用一个能让分析继续进行的符号串替换掉错误部分。
这种方式更精细,但实现更复杂。
出错产生式
在文法中专门增加一些描述常见错误结构的产生式,使分析器能识别某些典型错误并给出更明确的提示。
这种方式适合处理高频、模式明显的错误。
全局纠正
在所有可能修正方式中,寻找对输入串改动最少的一种,使修改后的串能被文法接受。这里的改动通常包括插入、删除和替换。
这种方式理论上更理想,但开销通常较大。
自顶向下分析
自顶向下分析的思想是:从文法开始符号出发,尝试一步步推导出给定的输入串。
例如文法:
Z -> aBdB -> dB -> cB -> bB
对输入串 abcd,可以做推导:
这个过程说明,自顶向下分析的本质是“从目标文法出发去匹配输入”。它的关键问题是:当一个非终结符有多个候选式时,当前到底该选哪一条产生式。
为了解决“如何选产生式”的问题,引入三个核心集合:First、Follow 和 Predict。
First 集
设 是上下文无关文法,,则:
也就是说,First(β) 表示:从 出发,可能首先出现的终结符集合;如果 能推出空串,还要把 ε 放进去。它的作用是看当前输入符号是否可能由某个候选式右部开头,从而决定是否选择该候选式。
Follow 集
对于非终结符 ,若 是开始符号,则:
<section class="footnotes"><div class="footnote-list"><ol><li><span id="fn:1" class="footnote-text"><span>要不然没法展开。 <a href="#fnref:1" rev="footnote" class="footnote-backref"> ↖</a></span></span></li></ol></div></section>